JetSpec: Causal Parallel Tree Drafting Hits 9.64x Faster LLM Inference


On June 26, 2026, researchers at UC San Diego’s Hao AI Lab released JetSpec — a speculative decoding method that accelerates large language model inference by up to 9.64× while leaving the model’s outputs unchanged. JetSpec trains a small “causal parallel draft head” on top of a frozen target model, generating a scored tree of candidate tokens in a single forward pass that the target then verifies all at once. Code and model weights are publicly available on GitHub and Hugging Face.
Advanced

The Scaling Ceiling JetSpec Breaks
Speculative decoding speeds up autoregressive generation by having a cheap “drafter” propose several tokens at once, then having the full target model verify them in a single forward pass. Verified tokens are accepted for free; the first rejected token forces a fallback. The technique is lossless — the accepted output is identical to what the target would have produced on its own — so the only question is how many tokens you can get accepted per round.
In theory, handing the drafter a larger budget (more candidate tokens, deeper trees) should mean more accepted tokens per round. In practice, gains plateau and even reverse — a “scaling ceiling.” JetSpec traces this to a causality–efficiency tradeoff in how drafters generate their trees:
- Autoregressive drafters (e.g., EAGLE-style) condition each draft token on the previous one, so their trees are faithful to the target’s factorization — but generating them token-by-token is slow, and the per-step overhead eats the speedup at large budgets.
- Block-diffusion drafters (the approach behind DFlash) emit a whole block in one shot — fast — but the branches aren’t conditioned on each other, so the tree’s scores don’t match the target’s autoregressive probabilities, and many branches get rejected.
JetSpec’s claim is that you don’t have to choose. Its draft head produces an entire scored tree in one forward pass (the efficiency of the diffusion approach) while still conditioning each branch on its parent (the faithfulness of the autoregressive approach).
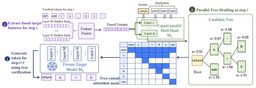
How the Causal Parallel Draft Head Works
JetSpec attaches a lightweight draft head to a frozen target model — only the head is trained, the target’s weights never change. At each generation step, the head reads fused hidden states pulled from multiple layers of the target, then expands a set of “anchor” and “draft slot” positions into a candidate tree in a single pass.
The key is the scoring. Each branch in the tree gets a score that is designed to align with the target’s own autoregressive factorization — so a high-scoring branch is genuinely likely to be accepted, not just locally plausible. The target then verifies the entire tree at once using a tree-causal attention mask, which lets every branch attend only to its own ancestors in a single batched forward pass.

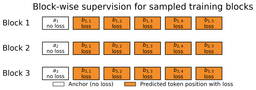
Training uses block-wise supervision with causal masking over anchor positions: anchor tokens carry no loss, while the predicted draft positions are supervised against the target. Notably, the authors report that this scheme needs no loss-weighting tuning across different budget settings — a practical win, since hyperparameter sensitivity is a common headache when scaling drafters. On a 50-prompt MATH-500 sample, JetSpec’s causal head kept 42% of its rank-1 branches faithful to the target, versus just 6% for a diffusion drafter — a direct measurement of why the trees survive verification.
Benchmark Numbers
On Qwen3-8B with a draft budget of 256 and greedy decoding, JetSpec reports:
- MATH-500: 9.64× speedup, 10.76 accepted tokens per round
- GSM8K: 7.82× speedup, 8.62 tokens per round
- HumanEval: 7.12× speedup, 7.78 tokens per round
- Open-ended chat: 4.58× speedup
At the engine level, JetSpec sustains roughly 1,000 tokens/second on average and peaks around 1,456 tokens/second. The authors say it outperforms the DDTree baseline on every benchmark at every budget level, and — importantly — that its speedup keeps climbing as the budget grows, where prior methods flatten out. The implementation ships its own paged FlashAttention kernels written in Triton and NVIDIA’s CuTe DSL, so it runs standalone without an external serving framework.
What This Means
Structured-reasoning workloads — math, code, agentic tool-use — are exactly the cases where these numbers matter most. Those tasks generate long, predictable token sequences where a faithful drafter can accept ten-plus tokens per round, which is why MATH-500 sees nearly 10× and open-ended chat (less predictable) sees ~4.6×. As inference, not training, becomes the dominant cost of running reasoning models in production, a lossless 5–9× on the right workloads is a meaningful lever.
JetSpec also continues a clear research thread the field has been pulling on all year: how to get drafters to propose more, better tokens per round. The Hao AI Lab has been a recurring name in that effort — the same group behind FastWan‘s sparse-distillation approach to video. JetSpec’s contribution is to show that the long-assumed tradeoff between one-pass drafting speed and branch-wise causal faithfulness was not fundamental — you can have both, and the scaling ceiling lifts when you do.
Related Coverage
- DFlash: Block Diffusion Delivers 6x Faster LLM Inference — the block-diffusion drafter JetSpec benchmarks its faithfulness against
- Gemma 4 Gets Multi-Token Prediction Drafters: 3x Faster Inference, Same Outputs — speculative decoding shipped as production drafters
- Luce DFlash Brings 2x Speculative Decoding to Qwen3.6-27B on a Single RTX 3090 — speculative decoding tuned for consumer GPUs


 沪公网安备31011502017015号
沪公网安备31011502017015号