Luce DFlash Brings 2x Speculative Decoding to Qwen3.6-27B on a Single RTX 3090


Luce DFlash now runs Qwen3.6-27B on a single RTX 3090, delivering up to 2× throughput over autoregressive decoding. The Lucebox Hub project, which hand-tunes LLM inference for specific consumer GPUs, ported its DFlash speculative decoding stack to Qwen3.6-27B in late April 2026. Because Qwen3.6-27B reuses the Qwen3.5 architecture string with identical layer and head dimensions, the existing DFlash draft model and DDTree verification stack load the new weights as-is — closing the gap between research-grade speculative decoding and 24 GB consumer hardware.
Advanced


What Changed With Qwen3.6-27B
Lucebox’s DFlash port originally targeted Qwen3.5-27B, where it posted some of the most aggressive consumer-GPU numbers seen this year: 207.6 tok/s peak versus 38.0 tok/s autoregressive (5.46×), 129.5 tok/s mean on HumanEval (3.43× speedup), 110.5 tok/s on Math500, and 96.2 tok/s on GSM8K — all on a single RTX 3090 with a Q4_K_M target plus BF16 draft model and a DDTree verification budget of 22.
Qwen3.6-27B, released April 22, 2026, ships the same Qwen35 architecture identifier and identical layer and head dimensions as its predecessor. That means the existing DFlash draft model and DDTree verification kernels load the new weights without retraining. Throughput on 3.6 lands lower than on 3.5 — the team reports “up to 2×” rather than the headline 5.46× peak — but it is the first published speculative-decoding stack of any kind running Qwen3.6-27B on a single 24 GB card.
How DFlash Works
DFlash, introduced in February 2026 by Z Lab (Jian Chen, Yesheng Liang, Zhijian Liu), replaces traditional autoregressive draft models with a block diffusion drafter conditioned on the target model’s hidden states. Instead of generating speculative tokens one-by-one, the drafter proposes an entire block in parallel; the target model then verifies the block in a single forward pass.
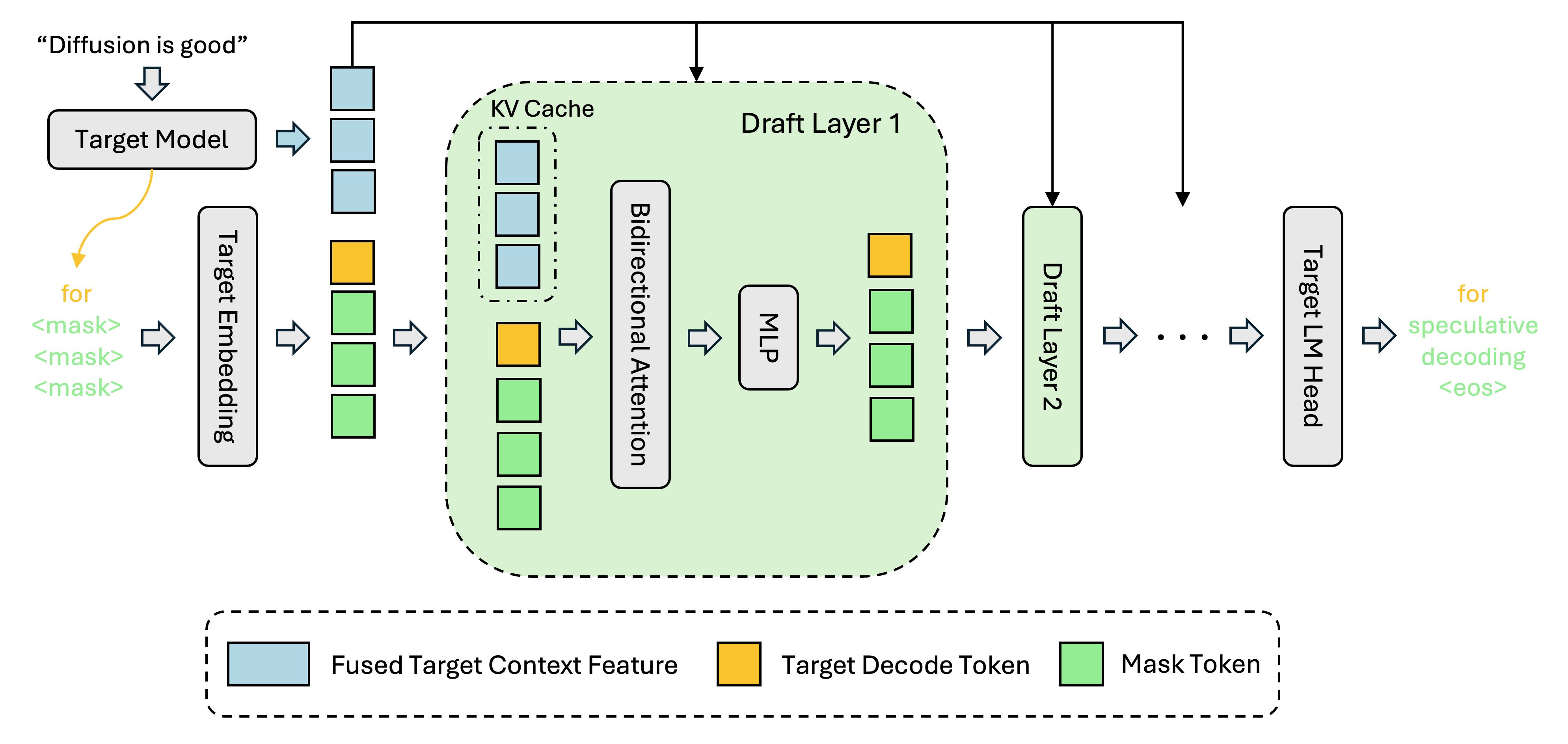
Z Lab’s reference benchmarks ran on B200 datacenter GPUs and reported 4.7× speedups on Math500 and 5.2× on HumanEval at concurrency 1 — but those numbers assume bf16 weights, FlashAttention 3, and 80 GB of HBM3. Lucebox’s contribution is engineering the same algorithm for a 24 GB Ampere card, which required several non-trivial changes:
- First GGUF port of DFlash — pinned to a
Luce-Org/llama.cpp@luce-dflashfork. - DDTree — tree-structured verification that beats chain verification, with the tree budget tuned to 22 for the RTX 3090’s VRAM and SM count.
- Three custom CUDA kernels for tree-aware SSM state rollback:
ggml_ssm_conv_tree,ggml_gated_delta_net_tree, andggml_gated_delta_net_tree_persist. - TurboQuant TQ3_0 KV cache — pushes the achievable context to 256K tokens within 24 GB; a 128K Q4_0 run still sustains 134.78 tok/s.
The stack supports CUDA 12+ and is compatible with Ada (RTX 4090), Blackwell (RTX 5090, requires CUDA 12.8+), and the DGX Spark / Jetson AGX Thor variants (sm_121 and sm_110, respectively).
Why Throughput Drops on 3.6
Qwen3.6-27B is architecturally compatible with the 3.5 draft, but it is not behaviorally identical. The release-day Qwen3.6-27B-DFlash drafter from Z Lab — still under training as of the April 26, 2026 snapshot — lands at roughly 78 tok/s on HumanEval with an acceptance length (AL) of 5.05, well below the 9.18 AL the same drafter reaches on Qwen3.5-27B. As the drafter trains to convergence on the new model’s distribution, the gap should close. Meanwhile, the existing 3.5 drafter still produces useful speedups when reused on 3.6 — just at lower acceptance rates and shorter trees.
What This Means
Speculative decoding has been the most-discussed inference optimization of 2026, but most of the published numbers come from datacenter GPUs running bf16 weights. Lucebox is one of the first projects to demonstrate that the same techniques can deliver multi-x speedups on quantized models running on a four-year-old consumer card — the kind of hardware that sits in research labs, classrooms, and home offices rather than hyperscaler clusters. Combined with TurboQuant’s 256K context and Qwen3.6-27B’s vision capabilities, the practical envelope of “what fits on one 3090” has expanded substantially in the last month alone.
Related Coverage
- Qwen3.6-27B: A Dense 27B Model That Beats a 397B MoE on Coding — the model this stack now accelerates.
- DFlash: Block Diffusion Delivers 6× Faster LLM Inference — the original Z Lab paper and method.
- Qwen3.6-35B-A3B: Alibaba Open-Sources a Frontier-Class Agentic Coder — the MoE sibling in the Qwen3.6 line.


 沪公网安备31011502017015号
沪公网安备31011502017015号