Qwen3.6-35B-A3B: Alibaba Open-Sources a Frontier-Class Agentic Coder


On April 2, 2026, Alibaba’s Qwen team open-sourced Qwen3.6-35B-A3B — the first open-weight variant of the Qwen3.6 generation. Released under Apache 2.0 on Hugging Face alongside the proprietary Qwen3.6-Plus API model, the 35-billion-parameter Mixture-of-Experts model activates just 3B parameters per token while posting frontier-level scores on agentic coding and reasoning benchmarks, including 73.4 on SWE-bench Verified and 92.7 on AIME 2026.
Intermediate

An Agentic-First Open Release
Where Qwen3.6-Plus stays closed behind Alibaba’s API and chatbot interfaces, Qwen3.6-35B-A3B was framed by the team with the tagline “Agentic Coding Power, Now Open to All.” The release continues Alibaba’s pattern of shipping a flagship proprietary tier and a developer-friendly open tier in tandem — the same playbook used for the Qwen3.5 family in February. The open weights are compatible with Hugging Face Transformers, vLLM (≥0.19.0), SGLang (≥0.5.10), and KTransformers, and an unsloth GGUF build appeared on Hugging Face within hours of launch.
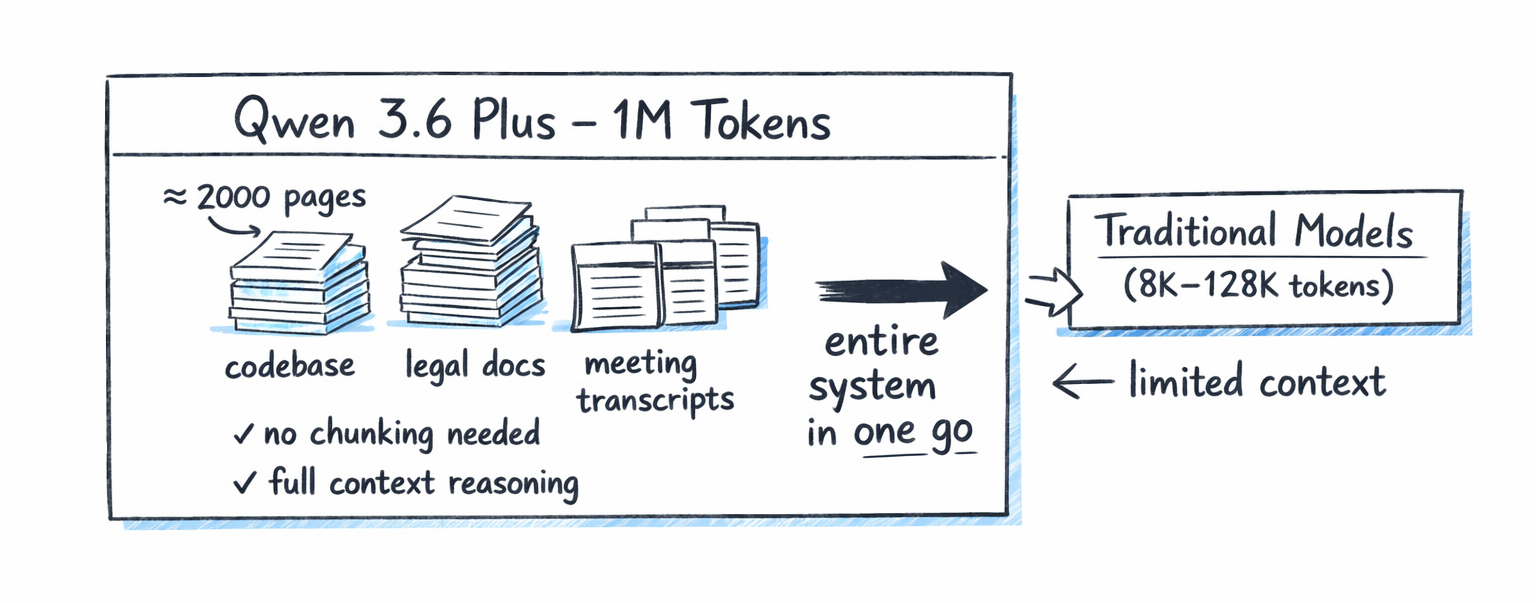
The model is natively multimodal, accepting text, images, and video through a built-in vision encoder. Native context length is 262,144 tokens, extensible to roughly 1.01M tokens with YaRN scaling — matching the long-context promise of the Plus tier.
Architecture: 256 Experts, Linear Attention, Multi-Token Prediction
Under the hood, Qwen3.6-35B-A3B is a sparse MoE with 256 experts, of which 8 routed plus 1 shared expert activate per token, yielding 3B active parameters. The 40-layer stack uses an unusual repeating block: three Gated DeltaNet (linear attention) layers followed by one Gated Attention layer, each paired with an MoE feed-forward block. Hidden dimension is 2048 and expert intermediate dimension is just 512, keeping per-token compute low. The team also trained the model with Multi-Token Prediction (MTP), a technique popularized by DeepSeek that improves training efficiency and enables faster speculative decoding at inference.
A new feature called thinking preservation retains reasoning context from prior turns in a conversation, so multi-step agentic workflows don’t lose their chain-of-thought between tool calls.
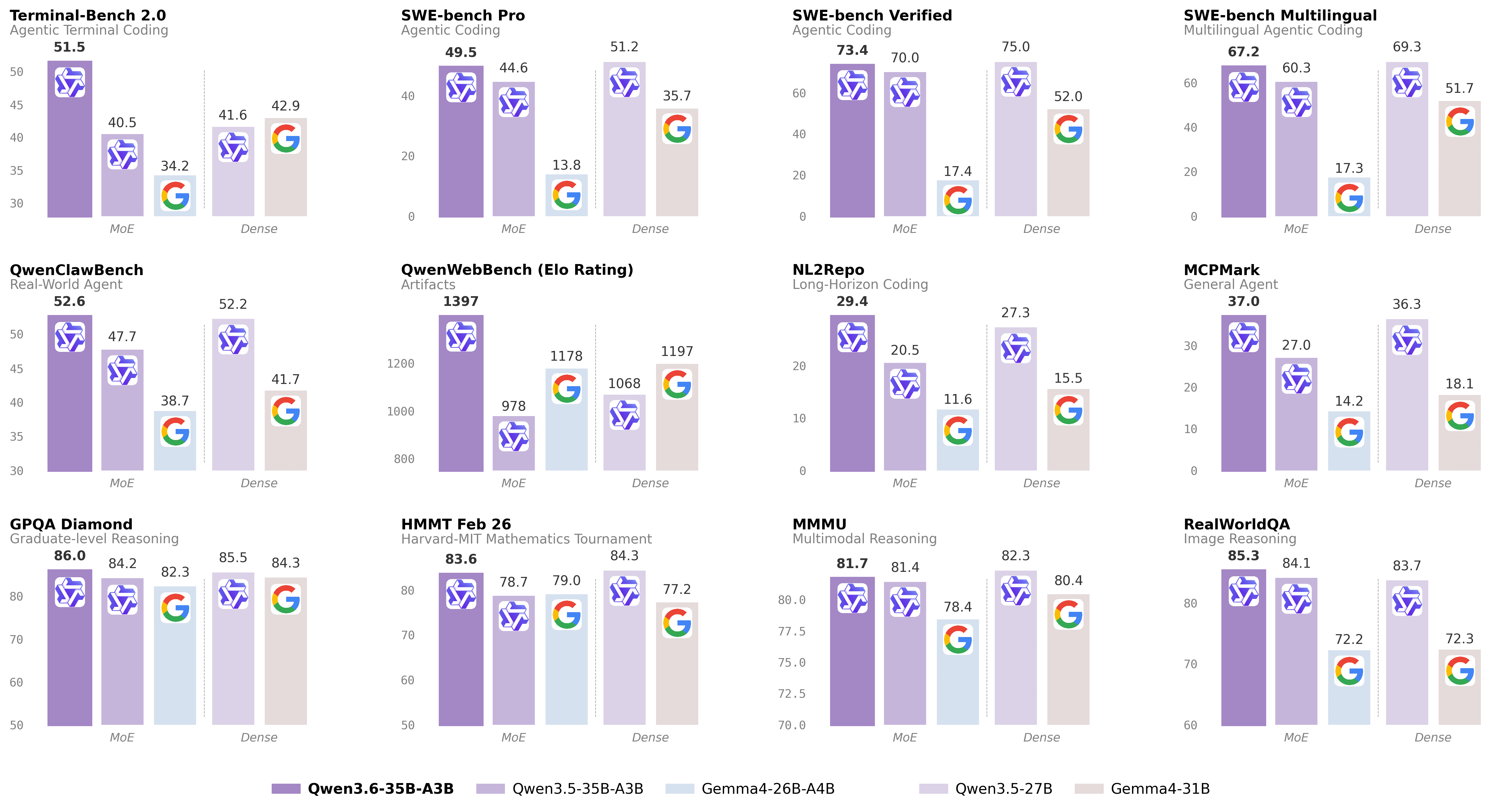
Benchmarks Punch Above the Weight Class
With only 3B active parameters, Qwen3.6-35B-A3B posts numbers that historically required dense models an order of magnitude larger:
- SWE-bench Verified: 73.4 — competitive with frontier closed models on real-world GitHub issue resolution
- Terminal-Bench 2.0: 51.5 — agentic shell-use evaluation
- MMLU-Pro: 85.2 and GPQA: 86.0 — broad and graduate-level knowledge
- AIME 2026: 92.7 and HMMT Feb 2026: 83.6 — competition mathematics
- MMMU: 81.7, RealWorldQA: 85.3, OmniDocBench: 89.9, VideoMMU: 83.7 — multimodal perception
The headline target for the release is clearly agentic coding: 73.4 on SWE-bench Verified is in the same neighborhood as the strongest closed models reported earlier this year, achieved by a model whose weights anyone can download.
What This Means
The 3B-active footprint matters. A developer with a single high-end consumer GPU — or a quantized GGUF on Apple Silicon — can now run a model that benchmarks alongside frontier agentic coders. Combined with the Apache 2.0 license, this puts repository-level coding agents and long-context multimodal reasoning into the hands of researchers, indie developers, and on-prem deployments that cannot rely on a closed API.
It also signals Alibaba’s continued strategy after the abrupt March departure of long-time Qwen tech lead Junyang Lin: the team is still shipping aggressively, and the open-source pipeline is intact.
Related Coverage
- CoPaw-Flash-9B: Alibaba’s Agentic Fine-Tune of Qwen3.5-9B — how Alibaba turned a small Qwen3.5 dense model into a local agent runtime
- Qwen3.5-Omni: Alibaba’s Omnimodal AI Speaks 36 Languages and Codes from Voice — the multimodal flagship from the prior generation
- Qwen 3.5 Small Models: 9B Parameters That Beat 120B — the small-model playbook Qwen has been refining
- Junyang Lin Steps Down as Qwen Tech Lead in Abrupt Departure — the leadership change just weeks before this release


 沪公网安备31011502017015号
沪公网安备31011502017015号