Huawei’s KVarN Hits 5x KV-Cache Capacity at FP16 Accuracy and Throughput


On June 2, 2026, Huawei researchers released KVarN — a variance-normalized KV-cache quantization backend for vLLM that breaks the long-standing tradeoff between cache compression and inference speed. KVarN delivers 3–5× more context capacity at 2-bit precision while keeping FP16-level accuracy and beating FP16 throughput, all behind a single vLLM flag with no calibration. It ships under Apache 2.0.
Advanced

The Problem: Quantization Errors Compound in Reasoning
The KV-cache — the stored keys and values from every previous token — dominates memory use during long-context and agentic inference. Quantizing it to 2 bits is the obvious way to fit more context on a GPU, but prior methods paid for that capacity in one of two ways: lower throughput or degraded accuracy. Huawei’s earlier comparison point, Google’s TurboQuant, hits 2.3–3.7× capacity but at “40 to 52% lower throughput.”
The KVarN paper pinpoints why aggressive KV quantization hurts reasoning specifically: errors accumulate across autoregressive decoding steps. The authors show that “the largest, e.g. top 5%, errors in the KV-Cache cause most of the end-to-end degradation,” and that these are driven primarily by incorrect token magnitudes — outlier tokens whose scale gets crushed by naive quantization — rather than directional distortion. Fix the outlier magnitudes, and most of the damage disappears.
How It Works: Rotate, Normalize, Quantize


KVarN runs each KV-cache tile through a four-stage pipeline before storing it:
- Hadamard rotation along the channel dimension spreads outliers across channels. Because the rotation is orthonormal, it preserves the attention scores exactly.
- Variance normalization — a Sinkhorn-like iterative algorithm that alternates column-wise and row-wise standard-deviation normalization in log space — equalizes variance across both the token and channel axes before quantizing.
- Asymmetric round-to-nearest quantization stores the values, with the normalization scales folded back at read time. Values land at 2 bits with dual FP8 scales and FP16 zero-points, for an effective 2.3 bits per element including the auxiliary parameters.
The overhead is tiny: 0.18% runtime for normalization and at most 1.4% for dequantization. Enabling it is one flag — no model surgery, no calibration pass:
vllm serve Qwen/Qwen3-32B \
--dtype float16 \
--kv-cache-dtype kvarn_k4v2_g128 \
--block-size 128The k4v2_g128 config allocates 4 bits to keys, 2 bits to values, per 128-token tile (one vLLM block).
The Numbers
At 2-bit precision, KVarN posts the best accuracy among KV-cache quantization methods on generative reasoning benchmarks. On MATH500, Qwen3-4B scores 79.2% (vs. 77.8% for KIVI, 77.0% for TurboQuant); the gap widens on harder models — Phi-4-14B jumps from 74.4% under KIVI to 84.8% under KVarN. On AIME24, Qwen3-4B improves from 55.5% to 60.0%, and on HumanEval Phi-4-14B leaps from 74.6% to 88.2%.
A line-retrieval stress test (600 lines of context) is where the accumulation problem shows starkest: Phi-4-14B retrieves at 95% accuracy under KVarN versus just 56% under TurboQuant. On instruction-following (IFEval), KVarN tracks FP16 within roughly half a percentage point across Qwen3-4B, Llama-3.1-8B, and Phi-4-14B.
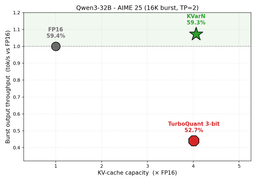
On the systems side, Huawei reports that for Qwen3-32B at a 16K-context burst (tensor-parallel 2), KVarN matches FP16 accuracy, delivers roughly 4× the KV-cache capacity, and runs at about 1.3× FP16 throughput — up to ~2.4× TurboQuant’s throughput at equivalent capacity, with higher accuracy.
What This Means
The recurring theme in KV-cache compression has been “pick two of three”: you could have capacity, accuracy, or speed. KVarN’s claim is that variance normalization lets you have all three at once, which matters most for exactly the workloads that have been hardest to serve — long-horizon agentic runs and multi-step reasoning, where a 5× capacity bump translates directly into longer context windows or more concurrent sessions on the same hardware.
Two practical caveats: the tile size is currently fixed at 128 tokens, and the public implementation is built on vLLM v0.22.0 with a specific key/value bit split. But as a calibration-free, drop-in backend, it lowers the barrier to 2-bit KV caching considerably. Combined with this year’s wave of inference-efficiency work — speculative decoding, multi-token prediction, and earlier quantization schemes — it pushes frontier-scale long-context inference further onto commodity GPUs.
Related Coverage
- Google’s TurboQuant Cuts LLM Memory 6x with Zero Accuracy Loss — the KV-cache quantization baseline KVarN measures itself against
- Gemma 4 Gets Multi-Token Prediction Drafters: 3x Faster Inference, Same Outputs — a parallel thread in inference-efficiency research
- Luce DFlash Brings 2x Speculative Decoding to Qwen3.6-27B on a Single RTX 3090 — squeezing more from a single consumer GPU


 沪公网安备31011502017015号
沪公网安备31011502017015号