Anthropic Releases Claude Opus 4.8 for Longer Agentic Coding


Anthropic released Claude Opus 4.8 on May 28, 2026, upgrading its flagship generally available model for long-horizon coding agents, professional knowledge work, and enterprise workflows. The release is not a radical architecture reveal; its significance is more practical: better benchmark results, a cheaper fast mode, stronger self-checking behavior, and new Claude Code workflows that let the model coordinate many subagents on large engineering tasks.
Intermediate
What Changed
Opus 4.8 is available as claude-opus-4-8 through the Claude API and is also available in Claude, Claude Code, Claude Cowork, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry, and GitHub Copilot. Anthropic says regular API pricing is unchanged from Opus 4.7 at $5 per million input tokens and $25 per million output tokens. The notable pricing change is fast mode: Opus 4.8 fast mode is listed at $10 per million input tokens and $50 per million output tokens, down from $30 and $150 for Opus 4.6/4.7 fast mode.
The Claude API documentation describes Opus 4.8 as supporting a 1 million token context window by default on the Claude API, Amazon Bedrock, and Vertex AI, with a 200,000-token context on Microsoft Foundry and up to 128,000 output tokens. It also keeps the Opus 4.7 API constraints: adaptive thinking is the supported thinking mode, and non-default sampling settings such as temperature, top_p, and top_k are not supported.
Benchmarks and Behavior
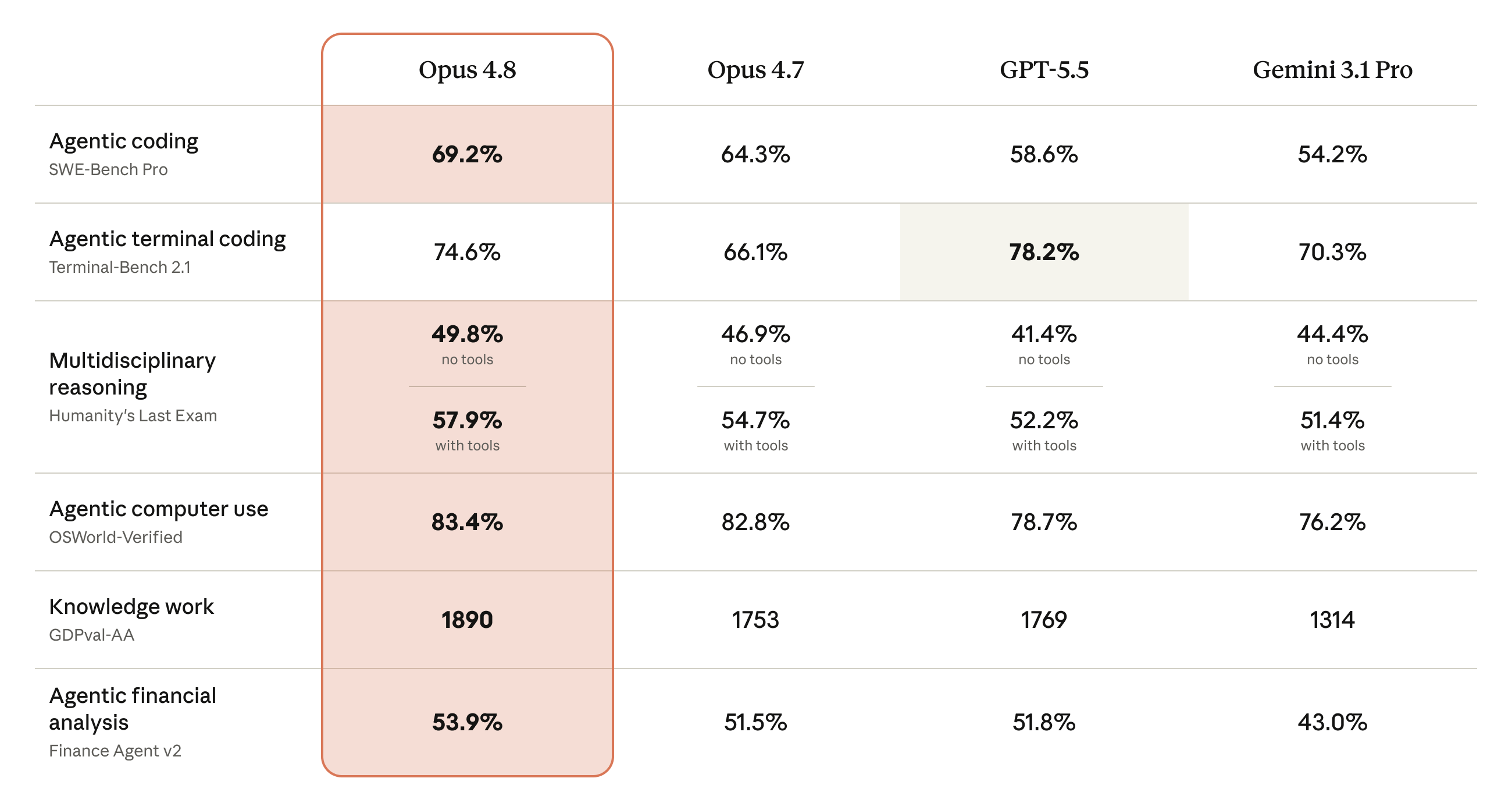
Anthropic’s benchmark chart puts Opus 4.8 ahead of Opus 4.7 on most of the release’s highlighted evaluations. On SWE-Bench Pro, Opus 4.8 scores 69.2%, compared with 64.3% for Opus 4.7, 58.6% for GPT-5.5, and 54.2% for Gemini 3.1 Pro. On OSWorld-Verified, it reaches 83.4%, narrowly above Opus 4.7’s 82.8% and above GPT-5.5’s 78.7%. It also leads Anthropic’s listed GDPval-AA knowledge-work score at 1890 and Finance Agent v2 at 53.9%.
The exception is Terminal-Bench 2.1, where Anthropic’s own chart shows GPT-5.5 ahead at 78.2%, with Opus 4.8 at 74.6%. That makes the release less of a clean sweep than a focused update: Opus 4.8 appears strongest where agentic coding, computer use, document-heavy work, and tool reliability matter together.
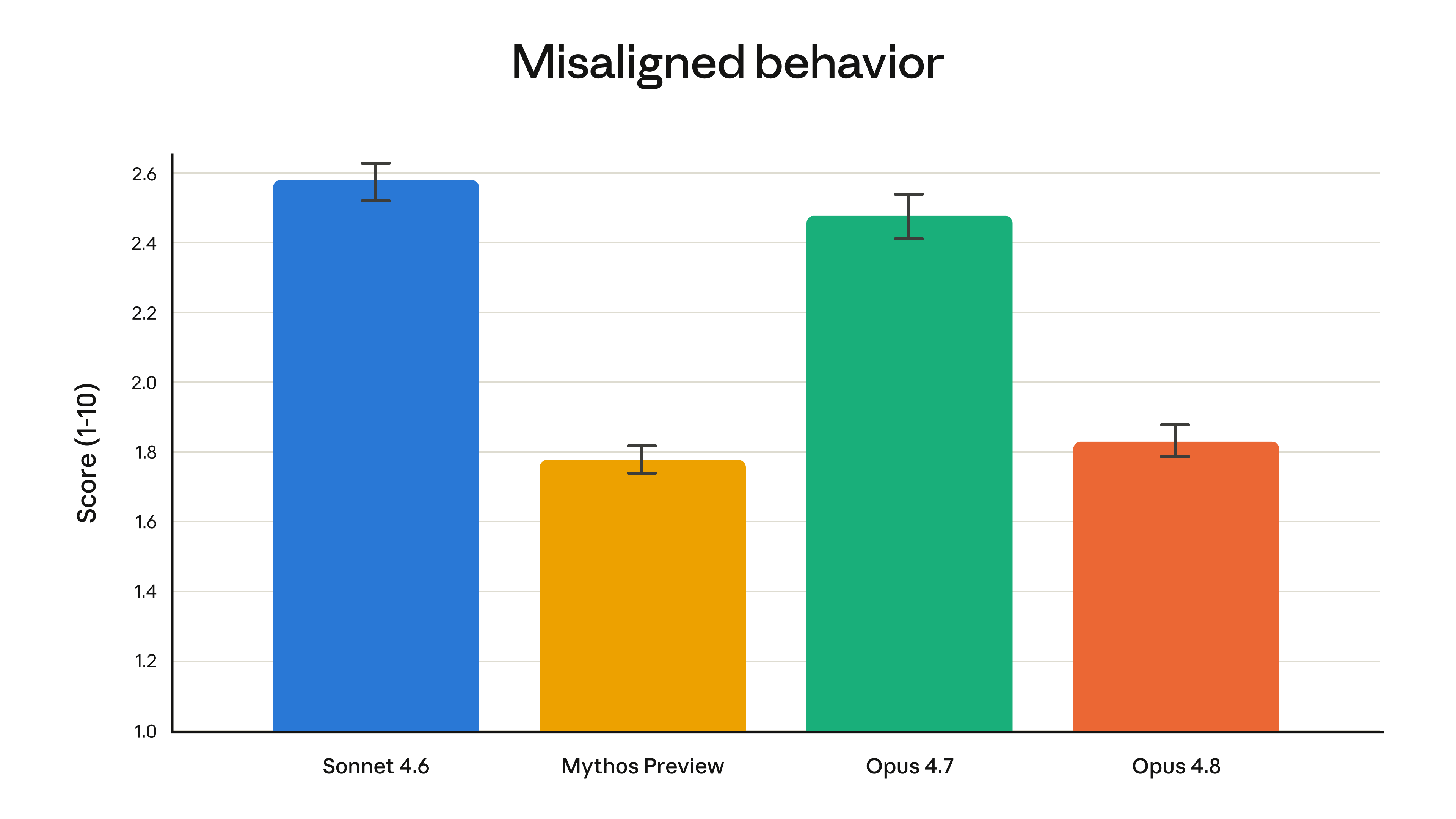
Anthropic also emphasizes reliability rather than only raw score gains. Its release notes say Opus 4.8 is around four times less likely than Opus 4.7 to leave flaws in its own generated code unmentioned. The company also reports lower measured misaligned behavior than Opus 4.7, with alignment results closer to Claude Mythos Preview.
Dynamic Workflows in Claude Code
The model release lands alongside dynamic workflows, a Claude Code research preview that lets Claude plan a large task, split it into subtasks, run tens to hundreds of parallel subagents, and verify outputs before reporting back. Anthropic frames this as a way to handle codebase-wide migrations, security audits, profiler-guided optimization, and high-stakes review tasks where a single-pass agent is too brittle.
The most aggressive example in the launch materials is a Bun port from Zig to Rust: Anthropic says dynamic workflows produced roughly 750,000 lines of Rust, reached 99.8% of the existing test suite passing, and took eleven days from first commit to merge. That example should be read as an early-access showcase rather than a normal developer workflow, but it signals where Anthropic wants Claude Code to move: from interactive pair programmer to orchestrated agent team.
What This Means
For developers already using Opus 4.7, Opus 4.8 looks like a drop-in upgrade with better tool use, stronger long-context behavior, cheaper high-speed inference, and no headline pricing increase for standard mode. For enterprises, the broader availability across Claude’s own products, AWS, Vertex AI, Microsoft Foundry, and GitHub Copilot matters as much as the benchmark deltas, because procurement and deployment channels often decide which frontier model a team can actually use.
The release also shows Anthropic separating two tracks: generally available Opus models for professional work, and higher-risk Mythos-class models that remain gated while cyber safeguards mature. Opus 4.8 is therefore less about unveiling a new intelligence ceiling and more about making the current ceiling more usable, cheaper to run quickly, and easier to trust during long-running agent work.
Related Coverage
- Anthropic Releases Claude Opus 4.7 With Sharper Coding and 3x Vision Resolution – the previous Opus release and the baseline for many of Anthropic’s comparisons.
- Anthropic Ships Agent View: A Multi-Session Dashboard for Claude Code – related Claude Code tooling for managing parallel agent sessions.
- Anthropic Launches Project Glasswing With Claude Mythos, the Model It Won’t Release – background on the gated Mythos-class capability referenced in the Opus 4.8 release.


 沪公网安备31011502017015号
沪公网安备31011502017015号