Anthropic Releases Claude Opus 4.7 With Sharper Coding and 3x Vision Resolution


Anthropic released Claude Opus 4.7 on April 16, 2026 — a direct upgrade to Opus 4.6 that focuses almost entirely on one thing: making the model better at long, hard software engineering work. The new release posts a 13% lift on Anthropic’s internal 93-task coding benchmark, resolves roughly 3x more production-grade tasks on Rakuten-SWE-Bench, and triples Claude’s maximum image resolution for the first time. Pricing is unchanged at $5/$25 per million input/output tokens, and the model is available today across Claude apps, the Anthropic API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
Intermediate


What’s new in Opus 4.7
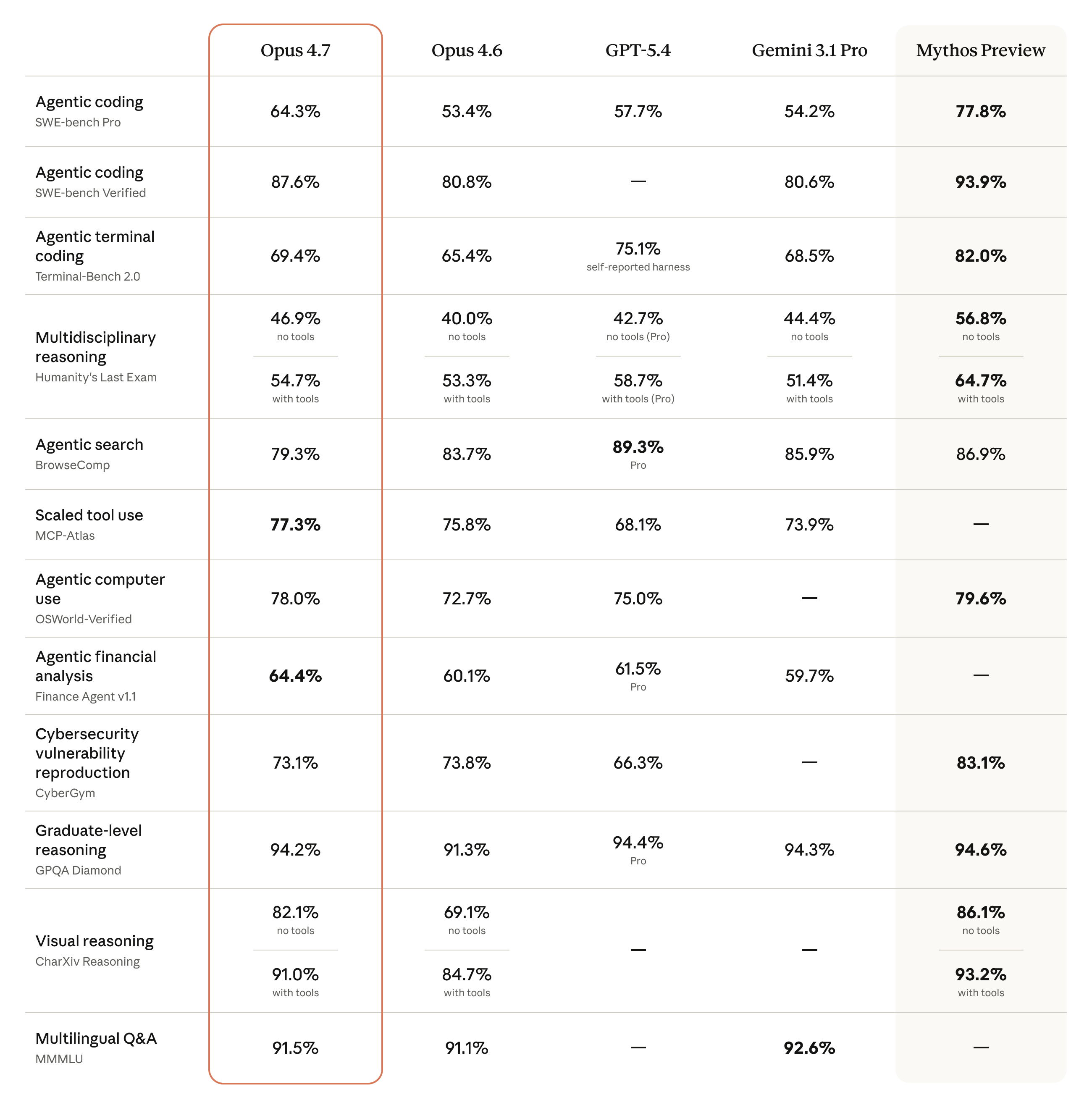
Anthropic frames Opus 4.7 as an incremental release, not a new tier — but the gains on the hardest tasks are anything but incremental. On Anthropic’s own 93-task coding evaluation, Opus 4.7 outperforms Opus 4.6 by 13 percentage points. On Rakuten-SWE-Bench, a harder suite built from real production engineering tickets, the new model resolves roughly three times as many tasks as its predecessor. Document reasoning errors on Databricks’ OfficeQA Pro fell by 21%, and on the XBOW visual-acuity benchmark Opus 4.7 jumped from 54.5% to 98.5%.
Those numbers reflect two underlying changes. First, Opus 4.7 is the first Claude model with high-resolution image support: the maximum image dimension moves from 1,568 pixels on the long edge (≈1.15 megapixels) to 2,576 pixels (≈3.75 megapixels), roughly 3x the visual capacity of previous Claude models. That matters most for computer-use agents reading dense screenshots, for diagram analysis, and for vision-heavy engineering tasks. Second, Anthropic introduced a new xhigh effort level sitting between high and max, giving developers finer-grained control over how much the model should think before answering.
Long tasks, better memory, fewer shortcuts
Anthropic says Opus 4.7 was shaped around “complex, long-running tasks” — the kind of multi-hour agentic work where earlier Claude versions tended to drift. The company highlights stronger adherence to literal instructions, better sustained reasoning over extended runs, and a file-system-based memory that holds up across multi-session work. The model also does more self-verification before reporting back, which Anthropic credits for a measurable drop in reward-hacking-style shortcuts.
Alongside the model, Claude Code picks up a new /ultrareview slash command for dedicated code review sessions (Pro and Max users get three free ultrareviews to start), Auto mode is extended to Max users, and the default effort level is raised to xhigh. On the API, task budgets — advisory token targets for agentic loops — enter public beta. Two API-side breaking changes land as well: extended thinking budgets are removed, and sampling parameters (temperature, top_p, top_k) are no longer supported on Opus 4.7.

The Mythos question
The release also reopens the awkward conversation Anthropic started earlier in April with Project Glasswing. In the Opus 4.7 announcement, the company acknowledges that the new model’s cyber capabilities are deliberately not as advanced as those of Claude Mythos Preview — the unreleased frontier model it decided was too dangerous to ship publicly. Anthropic says it “experimented with efforts to differentially reduce” cyber capabilities during Opus 4.7’s training, and is shipping with safeguards that automatically detect and block requests indicating prohibited or high-risk cybersecurity uses. A new Cyber Verification Program provides an authorized channel for vetted security researchers, penetration testers, and red-teamers.
Translation: Opus 4.7 is the strongest public Claude so far, but Anthropic is openly conceding its flagship trails its own unreleased model. For the rest of the market, the practical story is simpler — coding and agentic performance have moved forward at constant pricing, and Anthropic’s 1M-token context window remains included without a premium.
Related Coverage
- Anthropic Releases Claude Opus 4.6 with 1M Token Context Window — the February 2026 predecessor Opus 4.7 builds on.
- Anthropic Launches Project Glasswing With Claude Mythos, the Model It Won’t Release — context for Anthropic’s “too dangerous to ship” Mythos model referenced in the 4.7 announcement.
- Introducing Claude Opus 4.5 — the November 2025 release that kicked off the current Opus iteration cadence.
Sources
- Introducing Claude Opus 4.7 — Anthropic
- Anthropic releases Claude Opus 4.7, a less risky model than Mythos — CNBC
- Anthropic releases Claude Opus 4.7, concedes it trails unreleased Mythos — Axios
- Anthropic reveals new Opus 4.7 model with focus on advanced software engineering — 9to5Mac
- Anthropic’s Claude Opus 4.7 Released: All You Need to Know — felloai


 沪公网安备31011502017015号
沪公网安备31011502017015号