Qwen3.6-27B: A Dense 27B Model That Beats a 397B MoE on Coding


On April 22, 2026, Alibaba’s Qwen team released Qwen3.6-27B — the first dense open-weight model in the Qwen3.6 generation. Released under Apache 2.0 on Hugging Face, the 27-billion-parameter multimodal model posts flagship-level agentic coding scores that beat the team’s previous-generation 397B Mixture-of-Experts flagship across multiple benchmarks, while fitting into a 16.8 GB Q4_K_M quantization that runs on a single consumer GPU.
Intermediate
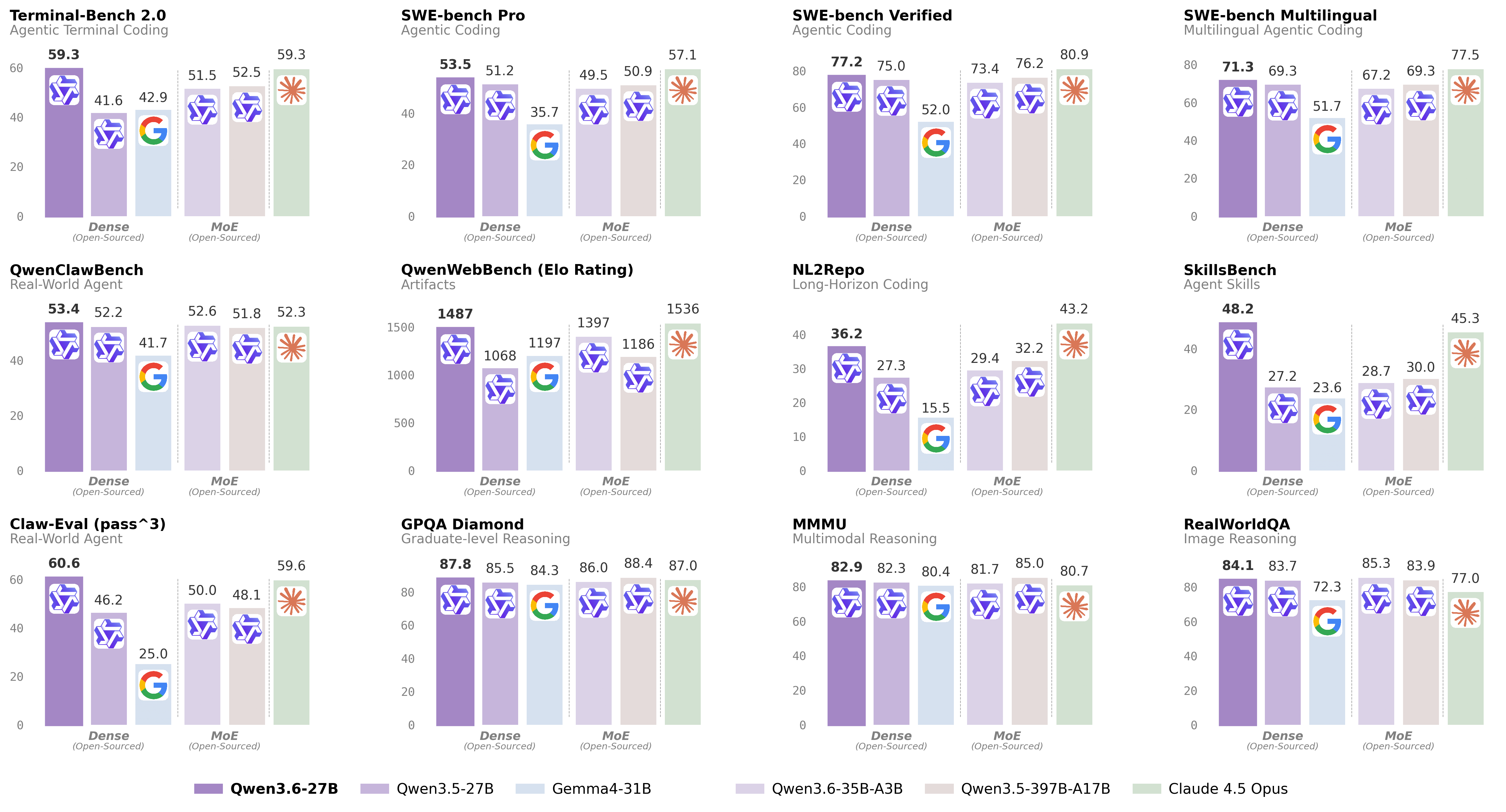
A 27B Dense Model That Beats a 397B MoE
The release’s headline result is that Qwen3.6-27B — a dense model with every parameter active on every token — outperforms Alibaba’s own Qwen3.5-397B-A17B MoE (17B active) across major coding benchmarks. On SWE-bench Verified, it scores 77.2 versus 76.2 for the 397B MoE. On Terminal-Bench 2.0 it jumps to 59.3 from 52.5, and on SkillsBench it posts 48.2 against 30.0. Against Anthropic’s Claude 4.5 Opus, the model is competitive rather than leading: Claude 4.5 Opus still edges ahead on SWE-bench Verified (80.9) and SWE-bench Pro (57.1), but Qwen3.6-27B matches it exactly on Terminal-Bench 2.0 (59.3) and comes within 3.3 points on MMLU-Pro (86.2 vs 89.5).
The dense-beats-MoE result is notable because the open-source community has spent the last year assuming that scaling raw parameter count via sparse experts was the cheapest path to frontier performance. Qwen3.6-27B suggests that architecture and training technique matter more than parameter bookkeeping — at least at this scale.
Hybrid Attention: Gated DeltaNet + Gated Attention
Under the hood, Qwen3.6-27B uses a hybrid attention stack that alternates linear and quadratic attention in a 3:1 ratio. The 64-layer network is organized as 16 repeated blocks, each containing three Gated DeltaNet sublayers followed by one Gated Attention sublayer (each paired with a feed-forward network). Gated DeltaNet is a linear-attention variant with O(n) complexity — 48 value heads and 16 query/key heads at 128 dimensions each. The quadratic Gated Attention layers use 24 query heads paired with just 4 key/value heads, minimizing KV cache overhead during long-context inference.
Native context is 262,144 tokens, extensible to just over one million with YaRN RoPE scaling. The model is trained with Multi-Token Prediction (MTP), and ships with a second feature the Qwen team calls Thinking Preservation: via a preserve_thinking flag in the API, reasoning traces from prior turns are retained in the context window, reducing redundant chain-of-thought regeneration during iterative agent workflows.

Fits on a Single Consumer GPU
The full BF16 weights are 55.6 GB; Unsloth’s Q4_K_M GGUF compresses that to 16.8 GB, which fits comfortably on a 24 GB RTX 5090 or 4090 with room for context. In independent testing, Simon Willison reported ~25 tokens/s generation via llama-server, noting the result was “outstanding for a 16.8 GB local model.” For comparison, the 397B MoE it outperforms weighs 807 GB at full precision — a ~48× file-size gap.
Official deployment paths include SGLang (≥0.5.10) and vLLM (≥0.19.0) for serving, with KTransformers offering heterogeneous CPU-GPU execution for memory-constrained setups. An FP8 variant (Qwen/Qwen3.6-27B-FP8) ships alongside the BF16 weights with 128-block fine-grained quantization. At publication time, 78 community quantizations were already available across llama.cpp, LM Studio, Jan, and Ollama.
Multimodal Capabilities
Despite the “coding model” framing, Qwen3.6-27B is natively multimodal. It posts 82.9 on MMMU, 81.4 on MMStar, 92.5 on RefCOCO average, 87.7 on VideoMME, and 94.7 on the V* visual-agent benchmark. On AndroidWorld — a test of GUI agent behavior on real Android apps — it reaches 70.3. That combination of agentic coding, long context, and vision in a single 27B package is what distinguishes this release from earlier Qwen checkpoints that had to pick one focus per model size.
What This Means
For researchers and practitioners running local or private-cloud inference, Qwen3.6-27B collapses a tier that previously required either a hosted API or multi-GPU MoE serving. A single-file quantized model that matches Claude 4.5 Opus on terminal-benchmark tasks, stays within 3–4 points on reasoning benchmarks, and runs on consumer hardware is a meaningful shift. It also continues the 2026 pattern of strong dense open-weight models closing the gap on proprietary frontier systems: the ceiling for what an Apache 2.0 model can do keeps rising.
Related Coverage
- Qwen3.6-35B-A3B: Alibaba Open-Sources a Frontier-Class Agentic Coder — the 35B MoE sibling released a week earlier
- Qwen 3.5 Small Models: 9B Parameters That Beat 120B — the previous generation’s efficiency story
- Qwen3.5-Omni: Alibaba’s Omnimodal AI Speaks 36 Languages and Codes from Voice — the multimodal predecessor
- Junyang Lin Steps Down as Qwen Tech Lead in Abrupt Departure — the team leadership change earlier this year


 沪公网安备31011502017015号
沪公网安备31011502017015号