IBM Releases Granite 4.1: Dense 8B Matches Prior 32B MoE Flagship


On April 29, 2026, IBM Research released the Granite 4.1 family — a refreshed lineup of dense, decoder-only language models in 3B, 8B, and 30B parameter sizes, plus updated speech, vision, embedding, and Guardian safety models. All weights ship under an Apache 2.0 license, and the headline result is striking: the new 8B instruct model matches or beats IBM’s prior flagship, the Granite 4.0 32B Mixture-of-Experts, on enterprise-relevant benchmarks while running on a far simpler architecture.
Advanced


What’s in the Release
Granite 4.1 spans more than just language models. The full collection includes:
- Language models at 3B, 8B, and 30B parameters, in base and instruct variants, with context windows up to 512K tokens.
- Granite Speech 4.1 — autoregressive and non-autoregressive 2B variants supporting multilingual transcription and translation, with a reported 5.33% word-error rate on the OpenASR Leaderboard.
- Granite Vision — a document-focused model using a DeepStack-inspired feature injection scheme that distributes visual information across multiple LLM layers, tuned for table, chart, and key-value extraction.
- Granite Embedding models for multilingual semantic search, expected to land at or near the top of the MTEB leaderboard.
- Granite Guardian 4.1, fine-tuned on the new 8B base with expanded risk definitions for safety evaluation.
Notably, the 4.1 LLMs return to a dense transformer design after IBM’s 4.0 generation experimented with hybrid Mamba/Transformer Mixture-of-Experts. The reversion isn’t a step back — it’s a bet that better data and training pipelines beat architectural complexity.
Architecture and Training Pipeline
All three models share standard modern transformer components: Grouped Query Attention (GQA), Rotary Position Embeddings (RoPE), SwiGLU activations, RMSNorm, and tied input/output embeddings. Per IBM’s technical writeup, the headline shapes are:
- 3B: 40 layers, embedding 2560, 40 attention heads, 8 KV heads, MLP hidden 8192
- 8B: 40 layers, embedding 4096, 32 attention heads, 8 KV heads, MLP hidden 12800
- 30B: 64 layers, embedding 4096, 32 attention heads, 8 KV heads, MLP hidden 32768
Pre-training spans roughly 15 trillion tokens across five phases. Phases 1 and 2 cover broad pre-training (10T tokens of CommonCrawl-heavy data, then 2T weighted toward math and code). Phases 3 and 4 anneal on progressively higher-quality data, including 12.5% long chain-of-thought traces and curated language and code instructions. Phase 5 stages a long-context extension from 32K → 128K → 512K tokens, using an 80% books / 20% code mix at the longest stage.


Post-training is where IBM puts much of its work. Supervised fine-tuning runs on ~4.1M curated samples (filtered with an LLM-as-Judge rubric for instruction following, correctness, completeness, conciseness, naturalness, and calibration), trained for 3 epochs across 16 nodes of 4× GB200 GPUs. Reinforcement learning then unfolds in four sequential stages using on-policy GRPO with the DAPO loss: multi-domain RL, RLHF (which alone adds +18.9 points on Alpaca-Eval), identity and knowledge calibration, and finally a math-specific RL stage that recovers a +23.48 point gain on DeepMind-Math versus pure SFT.
Benchmarks
The instruct numbers are competitive with the latest Gemma and Qwen dense releases. Selected scores from the IBM technical report:
- MMLU: 67.02 (3B) / 73.84 (8B) / 80.16 (30B)
- GSM8K: 86.88 / 92.49 / 94.16
- HumanEval: 79.27 / 87.20 / 89.63
- BFCL v3 (tool calling): 60.80 / 68.27 / 73.68
- RULER @ 128K (base models): 58.0 / 73.0 / 76.7

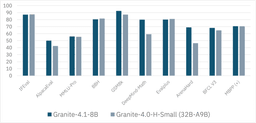
The most striking comparison is internal: Granite 4.1-8B matches or exceeds Granite 4.0-H-Small — a 32B-parameter MoE with 9B active parameters — on IFEval, AlpacaEval, MMLU-Pro, BBH, GSM8K, DeepMind-Math, EvalPlus, ArenaHard, BFCL v3, and MBPP. A carefully trained dense 8B is, in this comparison, a one-for-one substitute for the prior MoE.
What This Means
For enterprise teams, Granite 4.1 lowers the floor for “good enough” open models in two practical ways. First, the 8B can replace a much larger MoE on most tool-calling and instruction-following workloads, which simplifies serving — no expert routing, no load balancing across sparse experts, and friendlier behavior on commodity inference stacks. Second, the 512K context window plus strong RULER scores at long context make it credible for retrieval-heavy enterprise pipelines that previously required proprietary models.
It also reinforces a pattern worth watching across the open-weights ecosystem in 2026: Cohere’s Transcribe, Qwen’s recent dense releases, and now Granite 4.1 are all converging on the idea that training methodology — not parameter count or architectural novelty — is the binding constraint. The Apache 2.0 license, the public Hugging Face repository, and a published five-phase training pipeline make this one of the most reproducible enterprise-grade releases of the year.
Related Coverage
- Cohere Transcribe: 2B Open-Source ASR Model Takes #1 on Leaderboard — another recent Apache 2.0 enterprise model where small + carefully trained beat larger competitors.


 沪公网安备31011502017015号
沪公网安备31011502017015号