Cohere Transcribe: 2B Open-Source ASR Model Takes #1 on Leaderboard

On March 26, 2026, Cohere released Cohere Transcribe — a 2-billion-parameter open-source automatic speech recognition (ASR) model that claims the #1 spot on the Hugging Face Open ASR Leaderboard. Licensed under Apache 2.0 and designed to run on consumer-grade GPUs, Transcribe marks Cohere’s first entry into voice AI and signals growing competition in the open-source speech recognition space.
Intermediate


Architecture and Design
Cohere Transcribe uses a Conformer-based encoder-decoder architecture with an asymmetric design: more than 90% of its 2B parameters are dedicated to a Fast-Conformer encoder for acoustic representation, paired with a lightweight Transformer decoder for token generation. This approach minimizes autoregressive inference compute while maintaining transcription accuracy.
Unlike competitors such as Qwen3-ASR-1.7B and IBM Granite 4.0 1B Speech — which build on pre-trained text LLMs — Cohere Transcribe uses a dedicated architecture optimized specifically for speech-to-text inference speed and serving cost. The model was trained on 500,000 hours of curated audio-transcript pairs using standard supervised cross-entropy loss, with synthetic data augmentation and non-speech background noise (SNR: 0–30 dB) to improve robustness.
The model supports 14 languages: English, French, German, Italian, Spanish, Portuguese, Greek, Dutch, Polish, Chinese (Mandarin), Japanese, Korean, Vietnamese, and Arabic.
Benchmark Performance
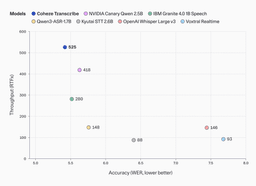
On the Hugging Face Open ASR Leaderboard, Cohere Transcribe achieves an average word error rate (WER) of 5.42%, outperforming all other models:
| Model | Avg WER | Parameters |
|---|---|---|
| Cohere Transcribe | 5.42% | 2B |
| Zoom Scribe v1 | 5.47% | — |
| IBM Granite 4.0 1B Speech | 5.52% | 1B |
| NVIDIA Canary Qwen 2.5B | 5.63% | 2.5B |
| Qwen3-ASR-1.7B | 5.76% | 1.7B |
| ElevenLabs Scribe v2 | 5.83% | — |
| OpenAI Whisper Large v3 | 7.44% | 1.6B |
The model also delivers up to 3x higher offline throughput than similarly-sized competitors, placing it on the Pareto frontier of the speed-accuracy tradeoff.

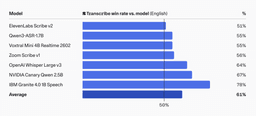
Human Evaluation and Multilingual Results
In pairwise human evaluation on English transcription, Cohere Transcribe achieved a 61% average win rate across criteria including meaning preservation, hallucination prevention, named entity recognition, and formatting. The strongest preference margins were against OpenAI Whisper Large v3 (64%) and IBM Granite (78%).

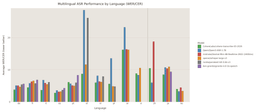
Multilingually, the model ranks 4th overall and 2nd among open-source models on the multilingual ASR leaderboard, with particularly strong results in Japanese (70% preference) and Italian (60% preference).

Availability and Deployment
Cohere Transcribe is available through multiple channels:
- Open-source download on Hugging Face under Apache 2.0
- Free API access (rate-limited) via the Cohere dashboard
- Model Vault — Cohere’s dedicated managed inference for production without rate limits
- vLLM integration with optimized batching for up to 2x throughput improvement
Cohere also plans to integrate Transcribe into its enterprise agent orchestration platform, North, expanding from pure transcription into broader speech intelligence capabilities.
Limitations
The model has some notable constraints: it does not support automatic language detection (a language code must be specified), lacks speaker diarization and timestamp output, and can hallucinate from non-speech sounds — Cohere recommends using voice activity detection (VAD) preprocessing for noisy audio.
Related Coverage
- Voxtral Transcribe 2: Mistral’s Open Real-Time Speech-to-Text — Mistral’s competing open-source ASR platform, released February 2026
- Qwen3-ASR & Qwen3-ForcedAligner Open Sourced — Alibaba’s production-ready ASR models, released January 2026
Sources
- Cohere Transcribe: a new state-of-the-art in speech recognition — Official Cohere blog
- Introducing Cohere-transcribe: state-of-the-art speech recognition — Hugging Face blog
- CohereLabs/cohere-transcribe-03-2026 — Model card on Hugging Face
- Cohere launches an open source voice model specifically for transcription — TechCrunch


 沪公网安备31011502017015号
沪公网安备31011502017015号