Z-Image: Alibaba’s Efficient 6B Open-Source Image Generation Model


Alibaba’s Tongyi MAI team has released Z-Image, a family of 6-billion-parameter image generation models that punches well above its weight class — achieving performance comparable to closed-source models with 20B+ parameters, at a fraction of the compute cost. Released in November 2025, Z-Image-Turbo ranked 1st among open-source models on the Artificial Analysis Text-to-Image Leaderboard, demonstrating that efficient architecture design can overcome raw parameter counts.

A Family of Specialized Models
Z-Image is not a single model but a suite of variants, each optimized for a different use case:
- Z-Image-Turbo: A distilled model for fast photorealistic generation, requiring only 8 inference steps with sub-second latency on H800 GPUs. This is the flagship variant for real-world deployment.
- Z-Image-Edit: Specialized for instruction-following image editing — making precise local or global changes while preserving image consistency.
- Z-Image-Omni-Base: The foundation model designed for fine-tuning, unifying both generation and editing in a single architecture.
All variants run comfortably in under 16 GB of VRAM, making them accessible on consumer-grade graphics cards — a rare distinction for a model of this quality.
Architecture: The Scalable Single-Stream Diffusion Transformer
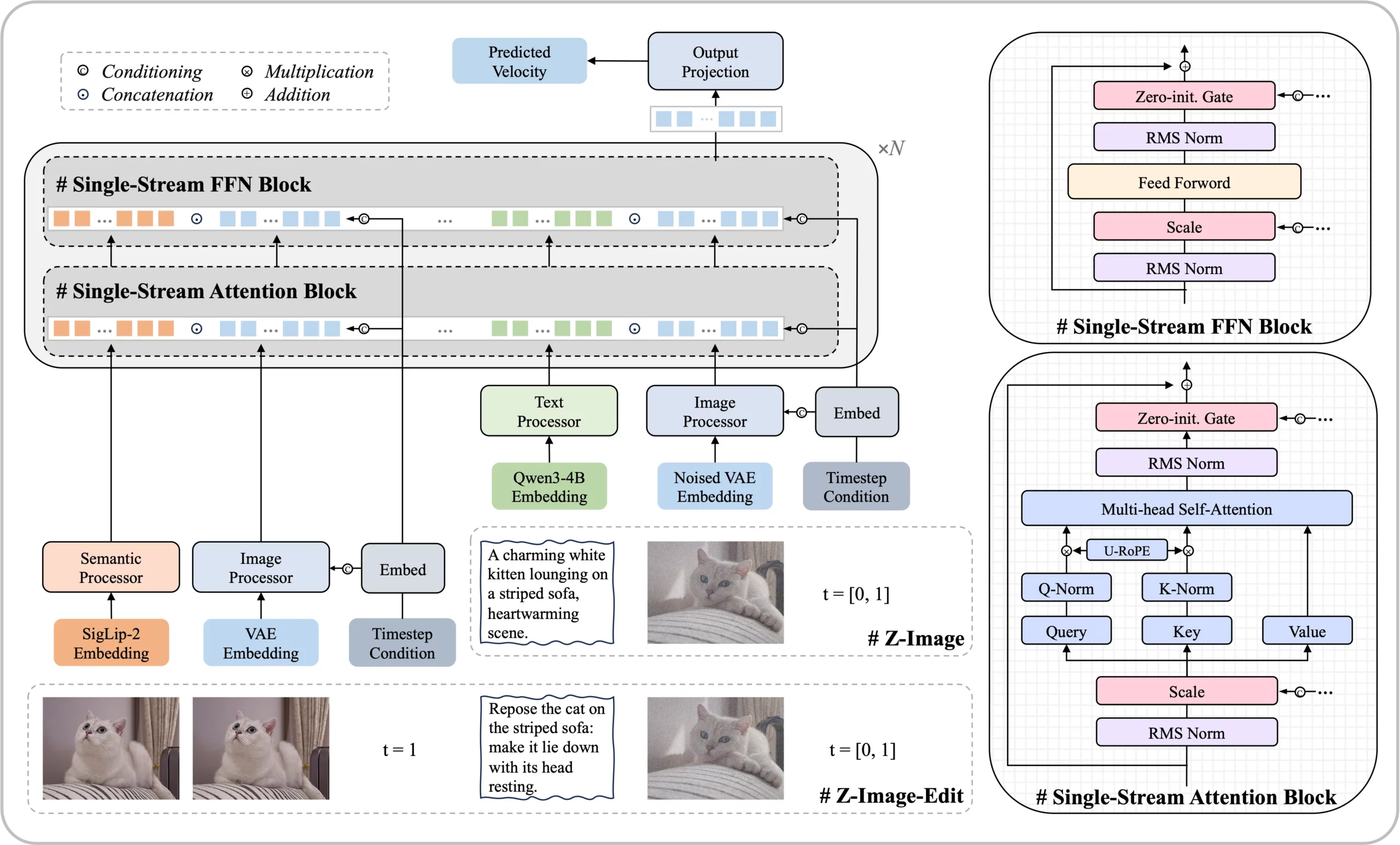
At the core of Z-Image is the Scalable Single-Stream Diffusion Transformer (S3-DiT), a 6.15B-parameter architecture with 30 transformer layers. Unlike dual-stream approaches that process text and image tokens in separate pathways, S3-DiT concatenates text embeddings, visual semantic tokens, and image VAE latents into a single unified sequence. This design maximizes parameter efficiency by allowing every layer to jointly attend over all modalities.
The system incorporates several components:
- Qwen3-4B as the text encoder for bilingual (Chinese and English) support
- Flux VAE for image tokenization
- SigLIP 2 for semantic understanding in the editing pipeline
- 3D Unified RoPE for positional encoding across mixed modalities
The full training pipeline consumed approximately 314,000 H800 GPU hours (roughly $628,000), spread across low-resolution pre-training, omni-pre-training at arbitrary resolutions, supervised fine-tuning, few-step distillation, and RLHF via Direct Preference Optimization.
Benchmark Performance
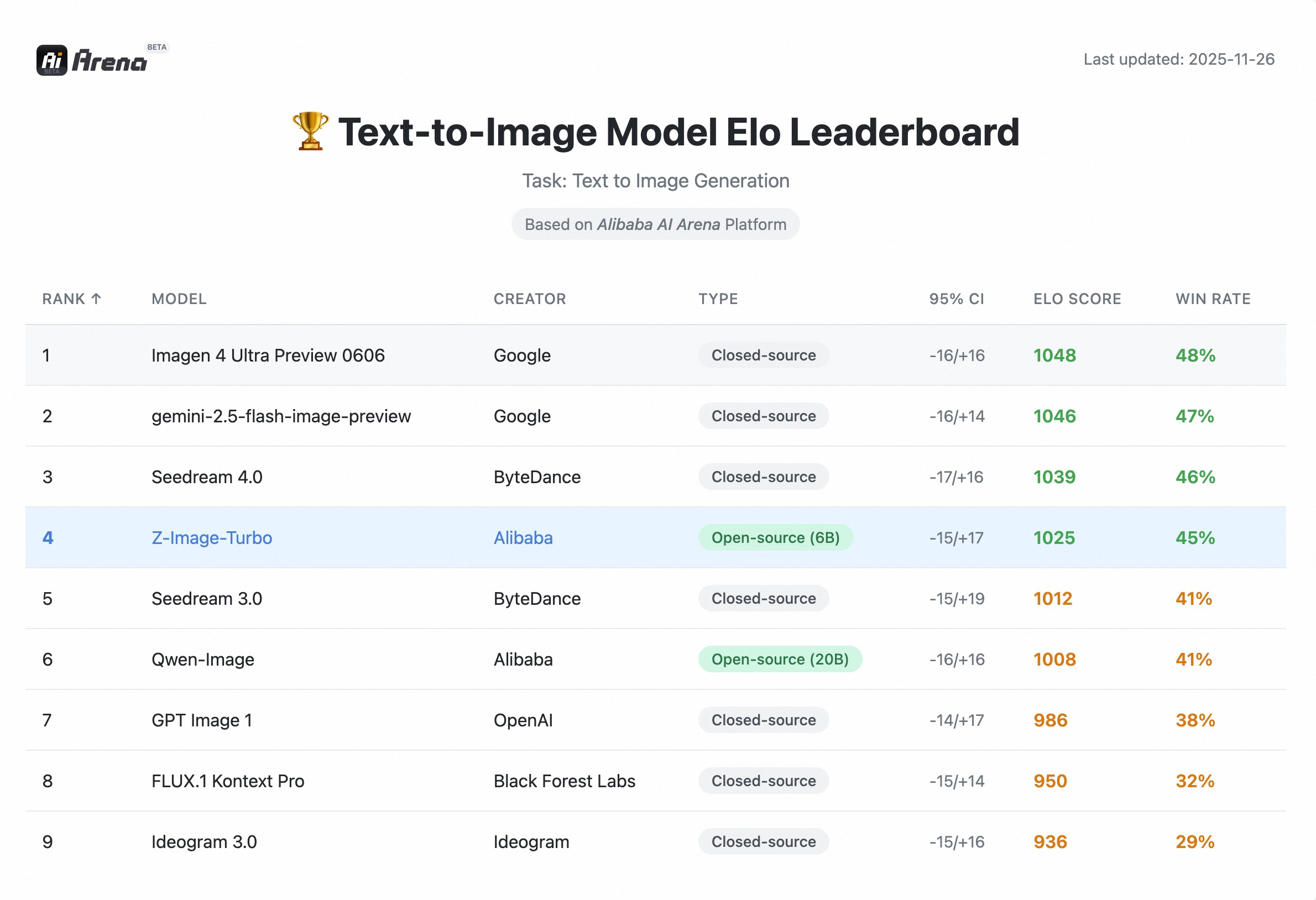
Z-Image-Turbo earned an Elo score of 1,025 on the Alibaba AI Arena human preference evaluation (as of November 26, 2025), placing it 4th globally and 1st among open-source models. It posted a 45% win rate across all matchups, including against leading closed-source systems.
On text rendering benchmarks — a historically weak point for image generators — Z-Image shines:
- CVTG-2K Word Accuracy: 0.8671, outperforming GPT-Image-1 (0.8569) and Qwen-Image (0.8288)
- LongText-Bench-EN: 0.935 (3rd place globally)
- LongText-Bench-ZH: 0.936 (2nd place globally)
Despite having roughly one-fifth the parameters of Flux 2 Dev (6B vs. 32B), Z-Image achieved an 87.4% “Good + Superior” rate in head-to-head user preference studies.
What This Means for Open-Source Image Generation
Z-Image is a notable step toward democratizing high-quality image generation. The combination of 6B parameters, sub-16 GB VRAM requirements, and top-tier open-source benchmark performance positions it as a practical alternative to much larger proprietary systems. Its native bilingual text rendering is especially valuable for Chinese-language creative applications, a segment where most Western models underperform.
The release follows a broader trend of Chinese AI labs — including Alibaba’s own Qwen team — demonstrating that architectural efficiency can be as important as raw scale. Researchers and developers can access Z-Image-Turbo weights on Hugging Face and ModelScope, with code available on GitHub.
Related Coverage
- Qwen-Image: Crafting with Native Text Rendering — Alibaba’s earlier 20B MMDiT-based image model with similar text rendering goals
- Qwen3-VL: The Next Generation Multimodal LLM from Qwen / Alibaba Cloud — Context on Alibaba’s broader multimodal strategy
Sources
- Z-Image Official Blog — Tongyi MAI
- Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer (arXiv)
- Z-Image GitHub Repository
- Z-Image-Turbo on Hugging Face
- Alibaba Tongyi Lab Releases Z-Image-Turbo — ComfyUI Wiki
- AI Image Generation for Consumer PCs: Alibaba Releases 6B Z-Image-Turbo Model — WinBuzzer


 沪公网安备31011502017015号
沪公网安备31011502017015号