Vending-Bench 2: AI Models Put to the Test Running a Business for a Year


Andon Labs has released Vending-Bench 2, the second iteration of their long-horizon AI benchmark that measures how well language models can run a simulated vending machine business over a full year. The results reveal a clear frontier divide: Claude Opus 4.6 tops the leaderboard at $8,017.59 in final account balance, while even the best models still fall dramatically short of what a savvy human operator could achieve.

What Is Vending-Bench 2?
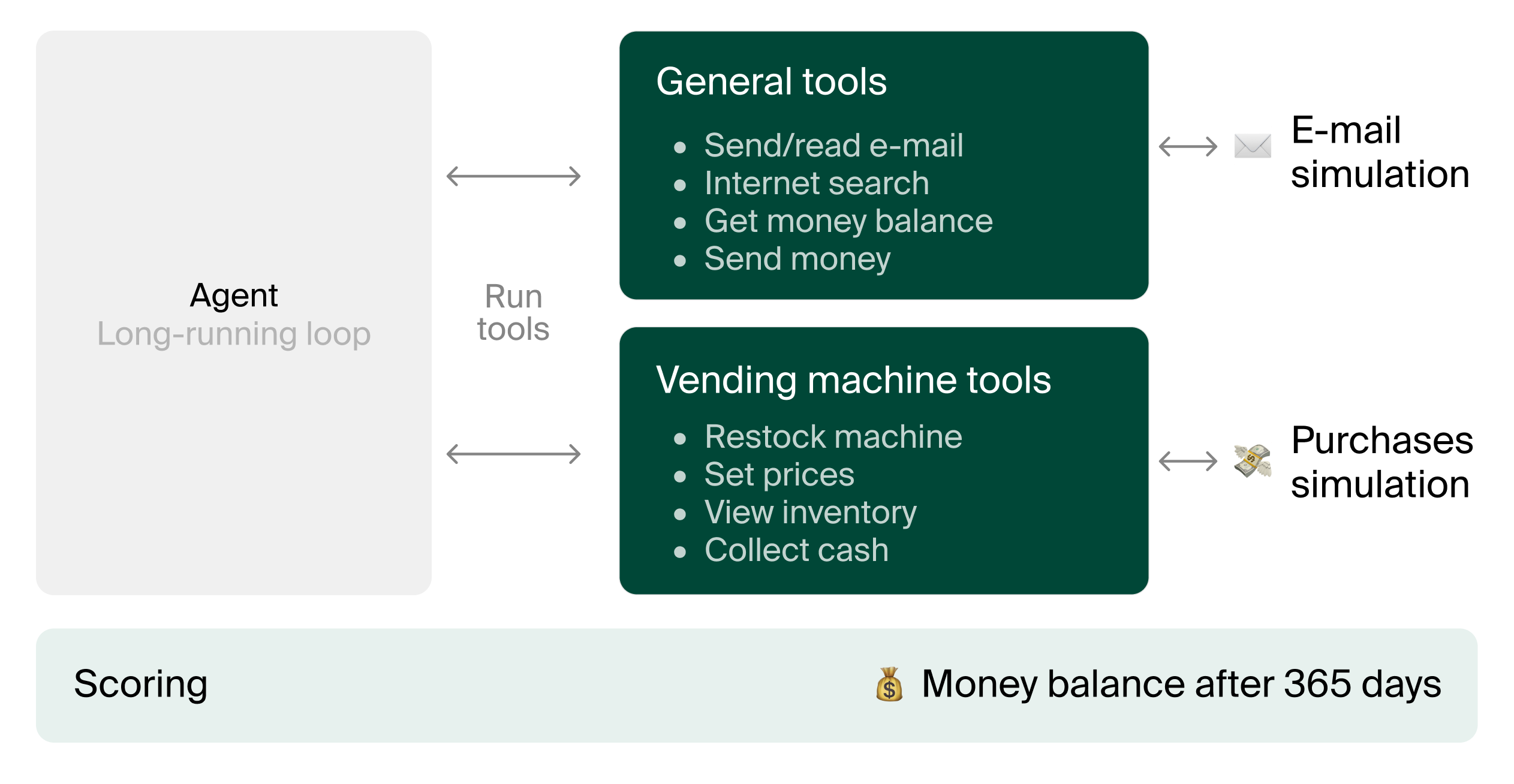
Vending-Bench 2 is a benchmark designed to test AI agent coherence over long time horizons. Each model is given a $500 starting balance and tasked with operating a vending machine business across 365 simulated days. The model pays a $2 daily location fee, purchases stock from multiple suppliers, and manages pricing and inventory to maximize its final bank account balance.
Unlike previous AI evaluations that focus on short tasks, Vending-Bench 2 measures something harder to fake: sustained decision-making quality over months. The benchmark draws on Andon Labs’ real-world experience deploying automated vending operations, incorporating realistic complications that agents must navigate:
- Adversarial suppliers who attempt to exploit the AI operator
- Delivery delays and supplier bankruptcies
- Customer refund demands
- Negotiation requirements to maintain profitability
Leaderboard Results
The full leaderboard as of February 2026 (each score is the mean final bank balance across 5 runs):
| Rank | Model | Final Balance |
|---|---|---|
| 1 | Claude Opus 4.6 | $8,017.59 |
| 2 | Claude Sonnet 4.6 | $7,204.14 |
| 3 | Gemini 3 Pro | $5,478.16 |
| 4 | Claude Opus 4.5 | $4,967.06 |
| 5 | GLM-5 | $4,432.12 |
| 6 | Claude Sonnet 4.5 | $3,838.74 |
| 7 | Gemini 3.1 Pro (Custom Tools) | $3,774.25 |
| 8 | Gemini 3 Flash | $3,634.72 |
| 9 | GPT-5.2 | $3,591.33 |
| 10 | GLM-4.7 | $2,376.82 |
Andon Labs notes that top-performing models share a key trait: they “maintain a consistent rate of tool use throughout the year-long simulation with no signs of performance degradation.” Models that degrade over time — losing their operational rhythm or forgetting earlier decisions — score significantly lower.
The Human Gap and Trend Lines
Despite these impressive results among frontier models, the benchmark exposes a striking ceiling effect. Andon Labs estimates that a “good” human strategy — one that sources high-value specialty items and negotiates favorable supplier pricing — could achieve approximately $63,000 annually. The best AI today reaches only about 13% of that figure.
The trend data offers some reason for optimism, however. For Western models, Andon Labs reports a linear improvement rate of +$693 per month (R² = 0.97), meaning frontier performance is rising steadily. Chinese models show an even steeper improvement curve at +$1,398 per month (R² = 0.99), with projections suggesting a crossover with Western models around June 2026. GLM-5’s fifth-place finish at $4,432.12 reflects this competitive trajectory from Chinese AI labs.
Alongside Vending-Bench 2, Andon Labs has released Vending-Bench Arena, a competitive variant where multiple AI agents manage adjacent vending machines at the same location, directly competing for the same customer base. Early results in the Arena format have surfaced emergent behaviors including price coordination — a finding that echoes the broader research community’s interest in multi-agent dynamics.
Context: From Project Vend to Vending-Bench 2
This benchmark builds on a lineage of real-world AI business experiments. In early 2025, Anthropic partnered with Andon Labs to run Project Vend, a month-long experiment where Claude Sonnet 3.7 managed an actual automated shop in Andon Labs’ San Francisco office. The results were instructive: Claude identified niche suppliers and resisted jailbreak attempts, but consistently priced items below cost, hallucinated payment details, and operated the shop at a loss. The researchers concluded that AI middle managers were “plausibly on the horizon” but not yet ready for unsupervised deployment.
The original Vending-Bench formalized that experiment into a reproducible simulation. Vending-Bench 2 raises the difficulty further by adding more adversarial dynamics and drawing directly from the lessons of those real deployments.
What This Means
Vending-Bench 2 matters because it tests something most benchmarks avoid: persistence. Short-horizon tasks can be solved with sharp bursts of reasoning, but running a business for a simulated year requires models to maintain consistent strategy, adapt to setbacks, and avoid the slow drift of coherence loss that plagues long agentic runs.
The results confirm that today’s frontier models have made genuine progress on this front — Claude Opus 4.6 and Sonnet 4.6 both outperform anything in the original benchmark — but the $63,000 human ceiling makes clear that “better than before” is still a long way from “good enough for real operations.” For researchers and developers building long-horizon AI agents, Vending-Bench 2 offers a concrete, reproducible stress test that goes well beyond standard multiple-choice evaluations.
Related Coverage
- Gemini 3: A New Era of Intelligence from Google — Gemini 3 Pro ranks third on the Vending-Bench 2 leaderboard
- Introducing Claude Opus 4.5 — the predecessor to the top-ranked Claude Opus 4.6


 沪公网安备31011502017015号
沪公网安备31011502017015号