Qwen3.5-Omni: Alibaba’s Omnimodal AI Speaks 36 Languages and Codes from Voice


On March 30, 2026, Alibaba’s Qwen team released Qwen3.5-Omni — a natively omnimodal AI model that processes text, images, audio, and video while generating real-time speech output. Available in three sizes (Plus, Flash, and Light), the model claims 215 state-of-the-art benchmark results and introduces features like semantic interruption, voice cloning, and an emergent “Audio-Visual Vibe Coding” capability that lets users generate code by speaking to the model while showing it visual references.
Intermediate

What’s New in Qwen3.5-Omni
Qwen3.5-Omni represents a major upgrade over the previous Qwen3-Omni series released in September 2025. The model was trained on over 100 million hours of native multimodal audio-video data, and its architecture has been rebuilt around the Hybrid-Attention Mixture-of-Experts (MoE) design that powers the broader Qwen 3.5 family. Both the Thinker (reasoning) and Talker (speech generation) components now use this sparse architecture, with specialized experts handling audio, video, and text processing separately while preserving single-modal performance.
The context window extends to 256K tokens — enough to process over 10 hours of audio or roughly 400 seconds of 720p video with audio in a single pass. Language coverage has expanded dramatically: speech recognition now spans 113 languages and dialects (up from 19 in Qwen3-Omni), and speech generation covers 36 languages (up from 10).
Performance Benchmarks
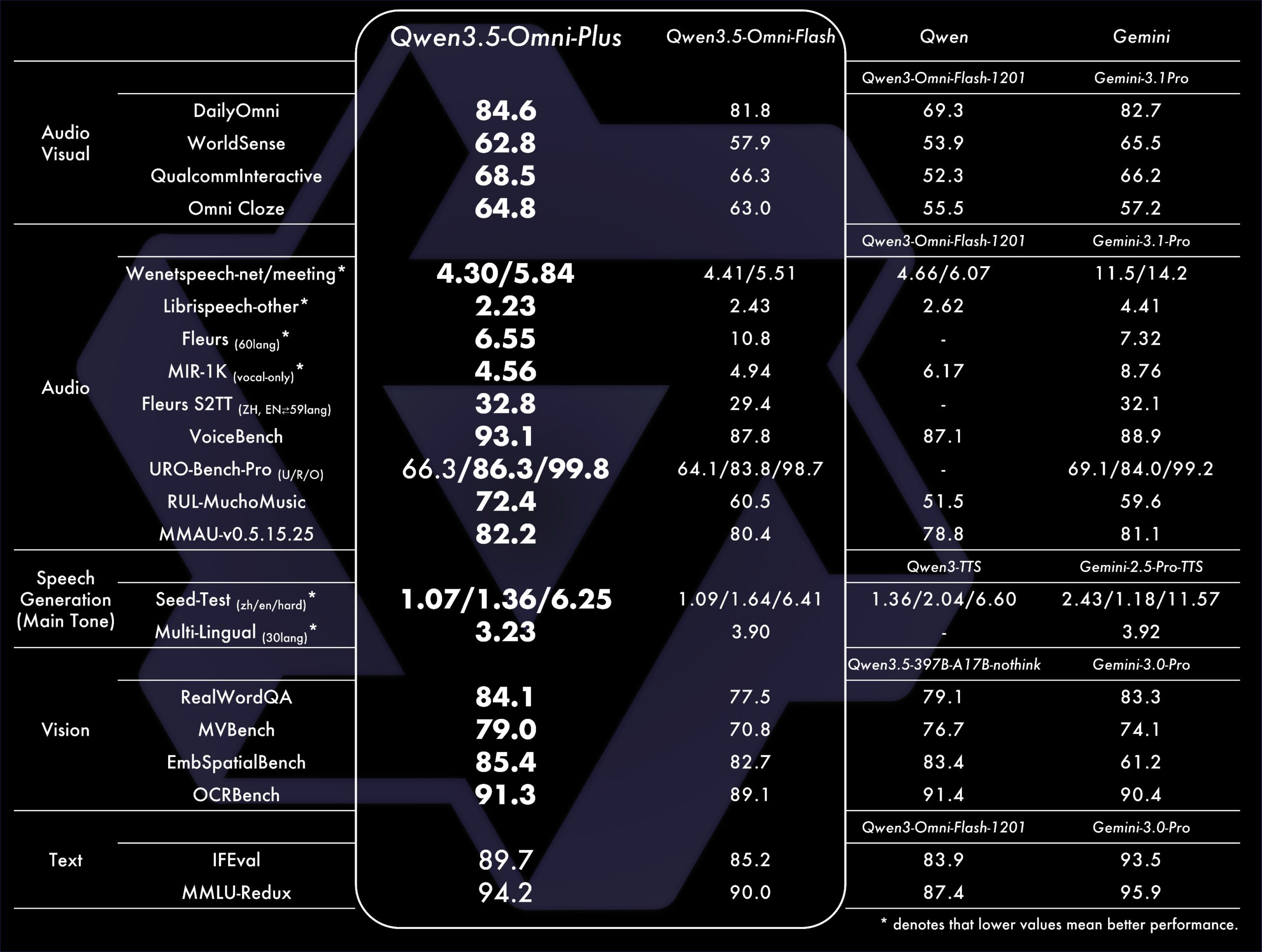
Alibaba claims the Plus variant achieved 215 SOTA results across audio, audio-video understanding, reasoning, and interaction benchmarks. Here are the headline numbers:
- Audio understanding: Outperformed Gemini 3.1 Pro on general audio understanding, reasoning, and translation tasks
- VoiceBench: Qwen3.5-Omni-Plus scored 93.1, approaching the top of the leaderboard
- Speech recognition: State-of-the-art on Librispeech, WenetSpeech, Fleurs, and CommonVoice benchmarks
- Vision: RealWorldQA score of 84.1, MVBench 79.0, OCRBench 91.3
- Text reasoning: IFEval 89.7, MMLU-Redux 94.2
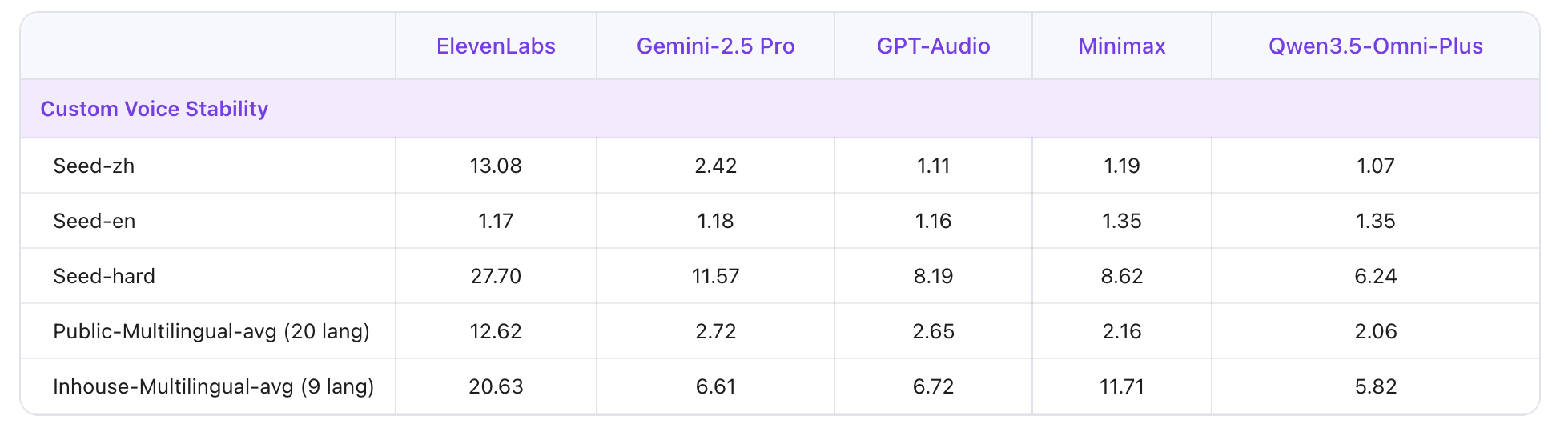
On multilingual voice stability, Qwen3.5-Omni-Plus beat ElevenLabs, GPT-Audio, and Minimax across 20 languages, achieving the lowest instability scores in both public and in-house multilingual benchmarks.
Key Features
Semantic Interruption — Unlike simple voice activity detection, Qwen3.5-Omni attempts to distinguish between a user genuinely wanting to interject and ambient background noise or passing comments. This makes real-time conversations feel more natural and less prone to false triggers.
Voice Cloning — The model can replicate a user’s voice from audio samples via the API, enabling the creation of custom AI assistants with consistent voice identities across sessions.
Audio-Visual Vibe Coding — Perhaps the most surprising capability: users can speak to the model while showing it visual references (mockups, diagrams, or existing UIs), and it generates working Python code or front-end prototypes. Alibaba says this ability “emerged without specific training,” suggesting it arose naturally from the model’s omnimodal pre-training.
ARIA Technology — Adaptive Rate Interleave Alignment synchronizes text and speech generation for more natural, well-paced audio output. Combined with native WebSearch and function calling support, Qwen3.5-Omni can serve as a real-time voice assistant that searches the web and takes actions mid-conversation.
What This Means
Qwen3.5-Omni continues Alibaba’s aggressive push to build a complete AI ecosystem around the Qwen brand. With speech, vision, and text unified in a single model — and open access via Alibaba Cloud’s API, Qwen Chat, and Hugging Face — Alibaba is positioning Qwen as a viable alternative to GPT-4o and Gemini for developers building voice-first and multimodal applications.
The emergent vibe coding capability is particularly noteworthy: it suggests that truly omnimodal training can unlock interaction patterns that no one explicitly designed for. For developers and researchers, the 256K context window and 113-language speech recognition make Qwen3.5-Omni one of the most versatile multimodal models available today.
Related Coverage
- Qwen 3.5 Small Models: 9B Parameters That Beat 120B — The compact Qwen 3.5 models for edge deployment
- Qwen 3.5: Alibaba’s Native Multimodal Agent Model Arrives — The flagship 397B MoE model release
- Junyang Lin Steps Down as Qwen Tech Lead in Abrupt Departure — Leadership change at Qwen
- Alibaba Unveils Qwen3-Omni Series — The previous Qwen3-Omni release
Sources
- Qwen3.5-Omni: Scaling Up, Toward Native Omni-Modal AGI — Official Qwen Blog
- Qwen 3.5 Omni: Alibaba’s AI Model Can Now Hear, Watch, and Clone Your Voice — Decrypt
- Qwen3.5-Omni AI Model: 215 SOTA Benchmarks & Vibe Coding — ToolMesh
- Qwen3.5-Omni Multimodal Voice Launch — AIHola
- Qwen3-Omni GitHub Repository


 沪公网安备31011502017015号
沪公网安备31011502017015号