NVIDIA Releases Kimodo: Controllable Text-to-Motion for Characters and Humanoid Robots


On March 16, 2026, NVIDIA released Kimodo — a kinematic motion diffusion model that turns text prompts and sparse kinematic constraints into high-quality 3D human and humanoid-robot motion. Trained on 700 hours of commercially-friendly optical motion capture data, Kimodo ships as an open-source project on GitHub and Hugging Face, with seven model checkpoints spanning the SOMA, Unitree G1, and SMPL-X skeleton formats. A v1.1 refresh followed on April 10, 2026.
Intermediate

What Kimodo Does
Kimodo is a diffusion-based motion generator: given a natural-language prompt (e.g. “a person walks forward, then crouches to pick something up”), it produces a sequence of joint rotations and root motion that drives a 3D character or humanoid robot. Crucially, the model also accepts kinematic constraints alongside text — full-body pose keyframes, end-effector positions and rotations, 2D ground waypoints, and path-following targets. This lets animators and roboticists steer the output at any point along the timeline without retraining.

The release includes a web-based interactive motion authoring tool with a timeline editor, a command-line interface for batch generation, and exporters for NPZ, CSV for MuJoCo, and the AMASS format. That makes Kimodo immediately usable both for graphics pipelines and for generating demonstration data to train physics-based control policies.
Architecture and Training Data
Under the hood, Kimodo uses a two-stage transformer denoiser that separately predicts the character’s root motion and the body’s joint rotations, with constraint conditioning injected through mask concatenation. The motion representation uses a smoothed root trajectory plus global joint rotations — a choice that simplifies physics retargeting downstream.
Training data is the project’s distinguishing claim. Kimodo was trained on the Bones Rigplay dataset — 700 hours of optical motion capture with corresponding text descriptions — plus the publicly released BONES-SEED subset for the variants intended to be reproducible by outside researchers. NVIDIA also published a Motion Generation Benchmark on Hugging Face (already at 142k downloads) so that other groups can compare directly against the SOMA-v1.1 checkpoints.
The collection on Hugging Face spans seven models: Kimodo-SOMA-RP-v1 and v1.1, Kimodo-SOMA-SEED-v1 and v1.1, Kimodo-G1-RP-v1 and Kimodo-G1-SEED-v1 for the Unitree G1 humanoid robot, and Kimodo-SMPLX-RP-v1 for the parametric SMPL-X human body model. The codebase is Apache-2.0; model weights are under the NVIDIA Open Model License or NVIDIA R&D Model License depending on the training source.
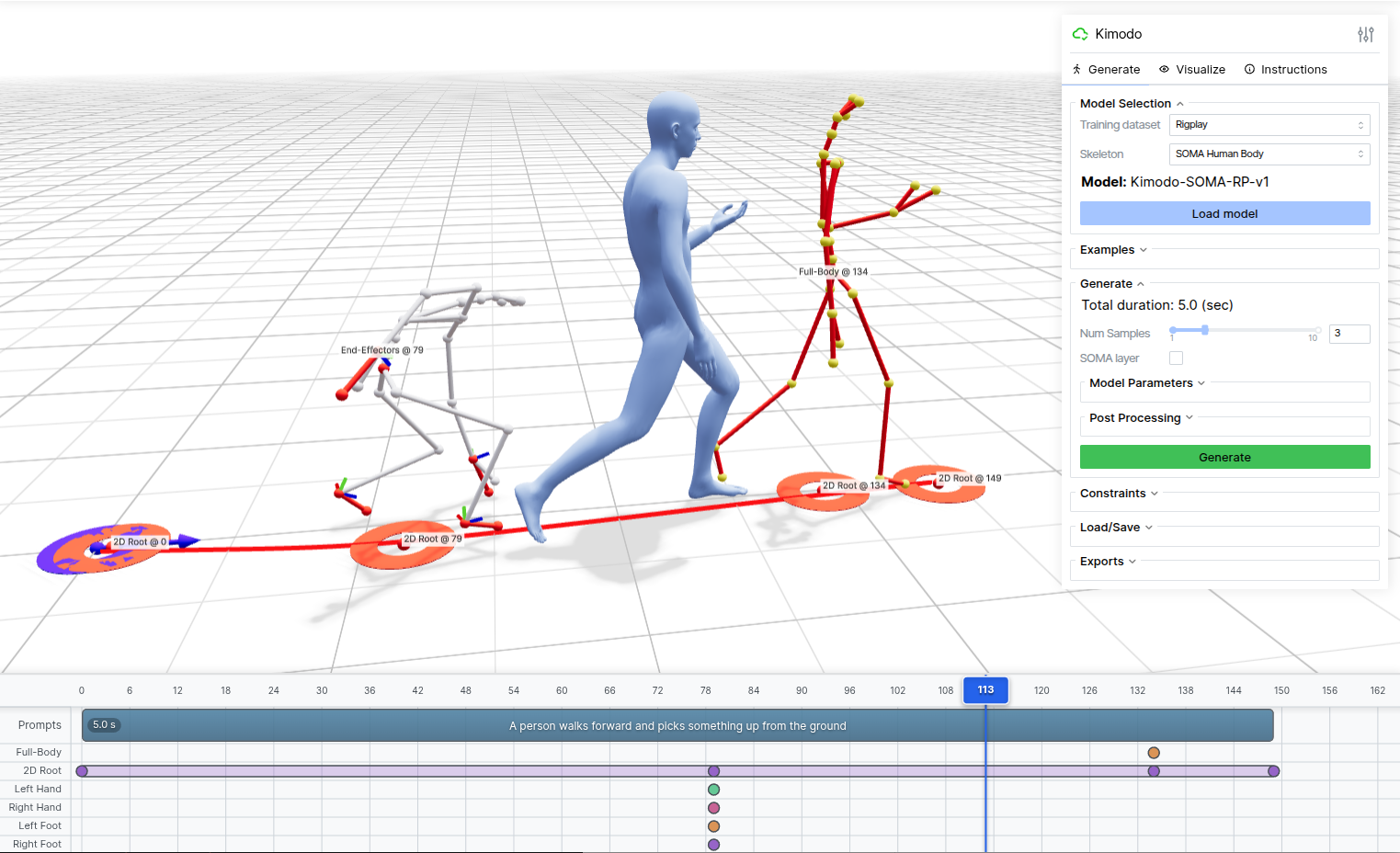
Why Robotics, Not Just Animation
Kimodo sits inside NVIDIA’s broader Physical AI push. The G1 variants generate kinematic motion for the Unitree G1 humanoid, and the project integrates with ProtoMotions and MuJoCo to convert generated motion into physically-trackable references for reinforcement learning policies. It also plugs into GEAR-SONIC, NVIDIA’s robot motion-tracking framework, which closes the loop from “text prompt” to “physical robot doing the thing.”

This is the practical case for text-to-motion in 2026: humanoid-robot training pipelines need vast, varied demonstration data, and hand-recording it on mocap stages or teleoperation rigs is the bottleneck. A controllable diffusion model that obeys both language prompts and kinematic constraints offers a scalable source of training trajectories.
What This Means
Open text-to-motion is becoming crowded — Tencent’s HY-Motion 1.0 covered similar ground last December — but Kimodo’s commercial-friendly training license, humanoid-robot skeleton support, and integration with the rest of NVIDIA’s Physical AI stack make it the most production-oriented release in the category to date. For graphics teams, it’s a usable animation co-pilot; for robotics labs, it’s a data source for policy learning. The standardized benchmark dataset on Hugging Face should also pressure the field toward apples-to-apples comparisons, which text-to-motion research has historically struggled with.
Related Coverage
- Tencent Open-Sources HY-Motion 1.0: A Billion-Parameter Text-to-Motion AI Model — the closest direct comparison in open text-to-motion.
- NVIDIA Launches Nemotron Coalition to Build Open Frontier AI Models — announced at GTC 2026 alongside the Kimodo open-source release.
- NVIDIA Nemotron 3 Super: 120B Hybrid Model Activates Only 12B Parameters for Agentic AI — part of NVIDIA’s recent open-model push.


 沪公网安备31011502017015号
沪公网安备31011502017015号