MiniCPM-V 4.6: A 1.3B Multimodal Model Built for Phones


OpenBMB released MiniCPM-V 4.6 on May 11, 2026 — the smallest entry in the MiniCPM-V family to date. At just 1.3B parameters, the new multimodal model handles single-image, multi-image, and video understanding while running on consumer phones across iOS, Android, and HarmonyOS. The model is open-weight under Apache 2.0 and ships with vLLM, SGLang, llama.cpp, and Ollama support out of the gate.
Intermediate

What’s new in version 4.6
MiniCPM-V 4.6 pairs a SigLIP2-400M vision encoder with a Qwen3.5-0.8B language backbone, building on the LLaVA-UHD v4 approach. The combined model is 1.3B parameters with a 262k-token context window — roughly 393 A4 pages of text equivalent. It accepts text, image, and video input (up to 128 frames with configurable frame stacking) and outputs text.
On the Artificial Analysis Intelligence Index, MiniCPM-V 4.6 scores 13, placing #3 of 28 models in its size class and well above the median of 8 for similarly-sized open-weight models. The team reports that the new model outperforms Qwen3.5-0.8B (score 10) at roughly 19× lower token cost, and the Qwen3.5-0.8B-Thinking variant (score 11) at 43× lower cost. On vision-language tasks specifically — OpenCompass, RefCOCO, HallusionBench, MUIRBench, OCRBench — the 1.3B model reportedly reaches Qwen3.5 2B-level capability.
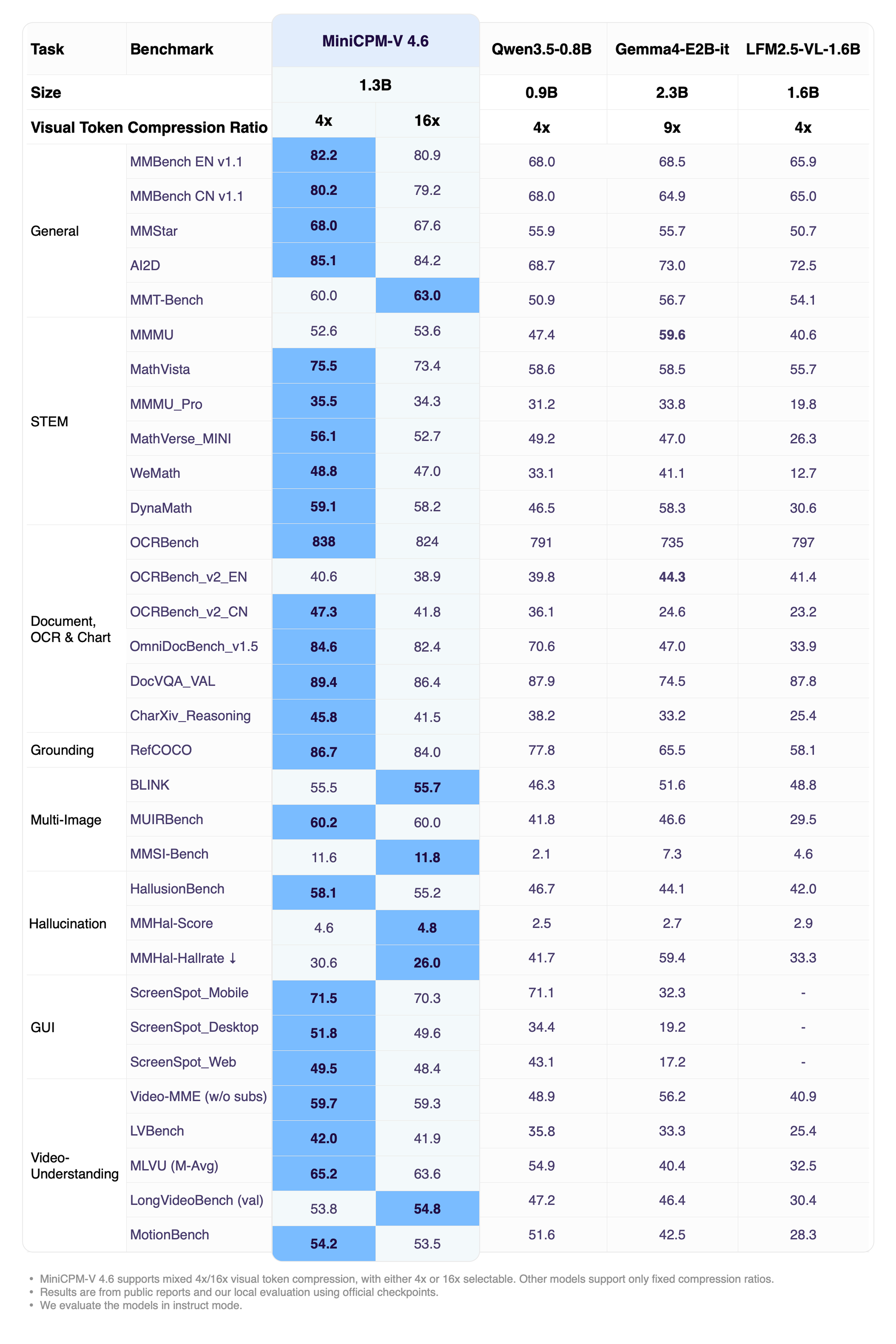
Efficiency gains that matter on-device
The 4.6 release puts most of its engineering effort into making the model genuinely usable on a phone, not a workstation. OpenBMB reports a greater-than-50% reduction in visual encoder FLOPs by introducing an intra-ViT early-compression stage, and they expose mixed compression rates — 16× for efficiency-leaning workloads and 4× when preserving fine visual detail matters (such as small-text OCR).
End-to-end token throughput comes in at roughly 1.5× that of Qwen3.5-0.8B, and the team has published time-to-first-token (TTFT) and high-concurrency throughput numbers alongside the model release.
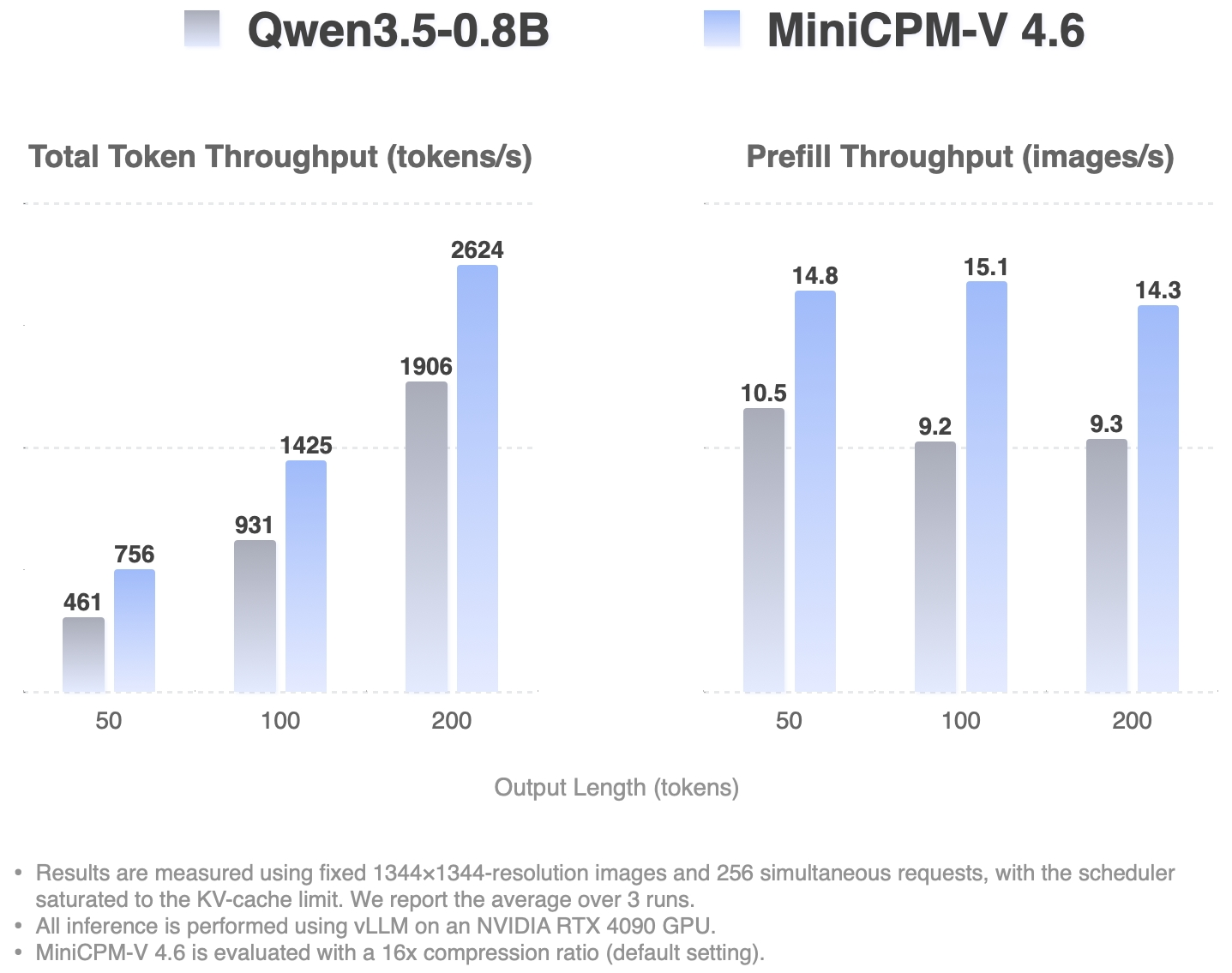
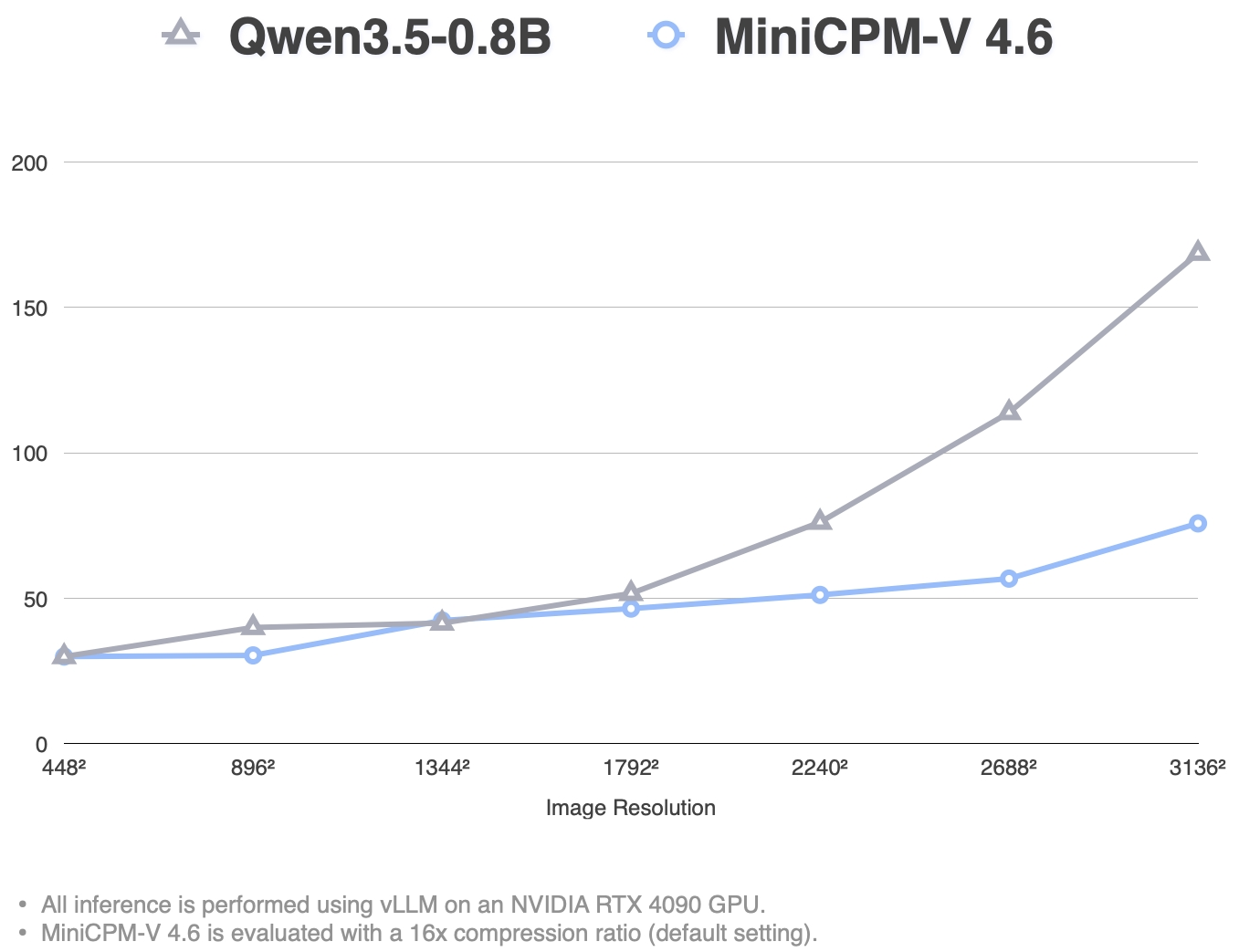
Eight quantized variants ship alongside the base weights — BNB int4, AWQ, and GPTQ all targeting roughly 3GB of GPU memory, plus a GGUF build that runs in around 2GB on CPU. The team also open-sourced edge adaptation code with reference demos on an iPhone 17 Pro Max (iOS), a Redmi K70 (Android), and a HUAWEI nova 14 (HarmonyOS), covering handwriting recognition, optical refraction reasoning, and receipt parsing respectively.
Why this release matters
The interesting framing for MiniCPM-V 4.6 isn’t whether it beats GPT-4 or Gemini — it doesn’t, and isn’t trying to. It’s that a 1.3B-parameter multimodal model with a 262k context window, real video understanding, and tool/function calling now fits inside the thermal and memory envelope of a phone, runs locally, and carries an Apache 2.0 license. For builders working on offline assistants, on-device document understanding, or privacy-sensitive consumer apps, the size-vs-capability point on the chart shifted meaningfully this week.
The model is available on Hugging Face at openbmb/MiniCPM-V-4.6 with a live demo space, fine-tuning support in LLaMA-Factory and SWIFT, and a community cookbook for edge deployment recipes.
Related Coverage
- Introducing VoxCPM 1.5 — previous OpenBMB-affiliated release covering open-source speech synthesis


 沪公网安备31011502017015号
沪公网安备31011502017015号