Meituan Open-Sources LongCat-2.0, a 1.6T Model Trained on Chinese Chips


Meituan has open-sourced LongCat-2.0, a 1.6-trillion-parameter Mixture-of-Experts model that the Chinese food-delivery giant says is the first model of its scale to complete both pre-training and inference entirely on domestic AI chips. Released on June 30, 2026, LongCat-2.0 had already been quietly topping OpenRouter’s usage charts under the codename “Owl Alpha” before its identity was revealed — and its near-frontier agentic-coding scores put it in the same conversation as GPT-5.5, Gemini 3.1 Pro, and Claude Opus 4.6.
Intermediate


A trillion-parameter model, trained without NVIDIA
The headline number is the hardware. According to Meituan, LongCat-2.0 was trained from scratch on a 50,000-card cluster of domestic AI ASIC superpods — Chinese-designed accelerators rather than NVIDIA GPUs. That is a meaningful step beyond what earlier Chinese flagships achieved: models like DeepSeek’s V4-pro have leaned on domestic chips for inference, but still relied on foreign silicon for the compute-heavy pre-training phase. Meituan claims LongCat-2.0 is the “industry’s first trillion-parameter model to complete full-process training and inference” on alternative hardware.
On the model side, LongCat-2.0 is a sparse Mixture-of-Experts (MoE) system with 1.6 trillion total parameters but only 33B–56B active per token (averaging roughly 48B), keeping inference cost far below the headline size. It ships with a native 1-million-token context window, made tractable by a custom linear-complexity attention mechanism the team calls LongCat Sparse Attention (LSA).
Benchmarks: near-frontier on agentic coding
LongCat-2.0’s strongest results are in agentic and coding tasks — the workloads that matter most for autonomous software agents:
- SWE-bench Pro: 59.5 — edging out reported numbers for GPT-5.5 (58.6) and sitting alongside Gemini 3.1 Pro and Claude Opus 4.6
- Terminal-Bench: 70.8 — emphasizing stable execution and error recovery in real shell environments
- SWE-bench Multilingual: 77.3
- BrowseComp: 79.9 and RW-Search: 78.8 for agentic web search
The model’s real-world footprint is the more striking signal. During its unbranded “Owl Alpha” residency on OpenRouter, it reportedly processed around 10.1 trillion tokens per month — roughly 559 billion tokens a day — ranking it among the top models globally by call volume before anyone knew it was Chinese.
How it’s built: distilling specialists into one model

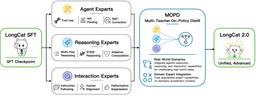
Rather than training one monolithic generalist, Meituan trained three specialized expert groups — an Agent expert (tool use, API parsing, self-correction), a Reasoning expert (multi-hop and STEM reasoning), and an Interaction expert (instruction-following, alignment, hallucination suppression). These are then fused into a single unified model through a technique the team calls MOPD (Multi-Teacher On-Policy Distillation), in which the specialist “teachers” transfer their capabilities into one student model.
Two efficiency tricks round out the design. “Zero-computation experts” let the network skip work for easy tokens, and a token-level dynamic-compute scheme (ScMoE) routes each token to only the experts it needs — which is how a 1.6T-parameter model can run with a 48B active footprint.
What this means
LongCat-2.0 lands at the intersection of two trends RITS readers have been tracking: the steady march of open-weight Chinese models toward the frontier, and the geopolitics of AI compute. A delivery company shipping a top-three-by-usage agentic coding model is itself notable — but doing it on a fully domestic training stack is the part that will be studied closely. If the full-process-on-Chinese-chips claim holds up under independent scrutiny, it suggests China’s path around NVIDIA export controls is maturing from “good enough for inference” to “good enough to train trillion-parameter frontier models.”
For practitioners, the open weights and aggressive OpenRouter pricing make LongCat-2.0 an immediately testable alternative for agentic coding workloads — and another data point that the open-source gap with closed frontier labs continues to narrow.


 沪公网安备31011502017015号
沪公网安备31011502017015号