Karpathy’s microGPT on FPGA Loses to a Single MacBook Core by 71x


A custom FPGA implementation of Andrej Karpathy’s microGPT was clocked at 53,000 tokens per second — and then promptly out-run by a single M4 Max MacBook P-core doing roughly 71× the throughput in plain C. The benchmark, published on May 2, 2026 by Alex Cheema, has reignited a long-running debate in the local-AI community: when is custom silicon actually worth it, and where do general-purpose CPUs still quietly dominate?
Advanced

The Two Halves of the Story
The story really starts in February, when Andrej Karpathy released microGPT — a 200-line, dependency-free Python file that trains and runs a GPT entirely from scratch. The model is intentionally minuscule: 4,192 parameters, character-level tokenization with a 27-token vocabulary, a single transformer layer, and a scalar autograd built from primitives. Trained on 32,000 names in about a minute on a MacBook, it generates plausible new ones like “kamon” and “karia.” Karpathy described it as “the culmination of multiple projects… and a decade-long obsession to simplify LLMs to their bare essentials.”


That tiny model became an irresistible target for a hardware port. Enter TALOS-V2, built by Luthira Abeykoon: a custom SystemVerilog RTL implementation of microGPT running on a DE1-SoC board with a Cyclone V FPGA. TALOS-V2 stores Q4.12 fixed-point weights in ROM, includes a hardware token sampler, and exposes a JTAG/MMIO control interface. The headline number from the project’s README: over 50,000 tokens per second.
The Benchmark That Flipped the Narrative
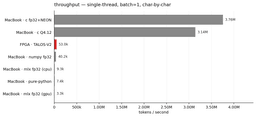
Cheema’s benchmark, titled bluntly talos-vs-macbook, asks a simple question: how does that 53,000 tok/sec FPGA compare to a well-tuned C implementation of the exact same model on a single P-core of an Apple M4 Max? The answer is striking.
- TALOS-V2 (Cyclone V FPGA): 53,000 tok/sec
- M4 Max P-core (single, well-tuned C): 3,756,165 tok/sec
- Throughput ratio: ~71× in favor of the MacBook
The workload was identical: single-token autoregressive inference at batch size 1, temperature 0.5. The model itself is roughly 17 KB at fp32 — small enough to live entirely in L1 cache — and a forward pass is only about 4,000 multiply-accumulates per token. Once compute is that cheap, latency and overhead dominate, and a modern CPU’s wide superscalar pipeline, branch prediction, and SIMD units leave a small FPGA fabric far behind.
Performance per Watt: The FPGA’s Last Stand
The conventional defense for FPGAs is energy efficiency. So Cheema measured that too. The Cyclone V on the DE1-SoC draws roughly 2 W under load; an M4 Max P-core under this workload sits closer to 5 W. That’s about 2.5× more power for the MacBook — but the MacBook is also doing 71× the work.

Net result: the MacBook wins on perf-per-watt by roughly 25–30×. The FPGA’s only remaining advantage is absolute power draw — useful for a battery-powered embedded device with a strict wattage ceiling, but not a general-purpose efficiency argument.
What This Means
The benchmark is, in fairness, a deliberately uncharitable case for FPGAs. A 4,192-parameter model is so small that it never escapes the CPU’s cache hierarchy, eliminating the memory-bandwidth bottleneck where custom silicon usually pays off. Real production LLMs — even modest 1B–8B parameter models — are dominated by weight movement from HBM or DDR, and that’s where ASICs and well-designed FPGA accelerators tend to claw back orders of magnitude over CPUs.
But the result is still a useful corrective. It shows how easy it is to publish an impressive-sounding FPGA throughput number (“50k+ tkps!”) that evaporates the moment someone writes the obvious C baseline. It also underscores why the local-AI hardware conversation has shifted toward unified-memory APUs and high-bandwidth consumer GPUs rather than bespoke FPGA boards: the software stack, the memory hierarchy, and the cache behavior matter more than the raw clock speed of any single arithmetic unit.
For students and researchers, the lesson is older than transformers themselves: always benchmark against a competent baseline on commodity hardware before claiming a hardware win. And for anyone tempted by a Cyclone V on eBay this weekend — your laptop is probably faster.
Related Coverage
- Karpathy Open-Sources Autoresearch: 100 AI Experiments Overnight on One GPU — Karpathy’s earlier minimalist research framework from March 2026.
- Effortless Git Repository Visualization with RenderGit — Another Karpathy single-file tool in the same minimalist tradition.


 沪公网安备31011502017015号
沪公网安备31011502017015号