Hugging Face Releases ml-intern: An Open-Source Agent That Automates Post-Training


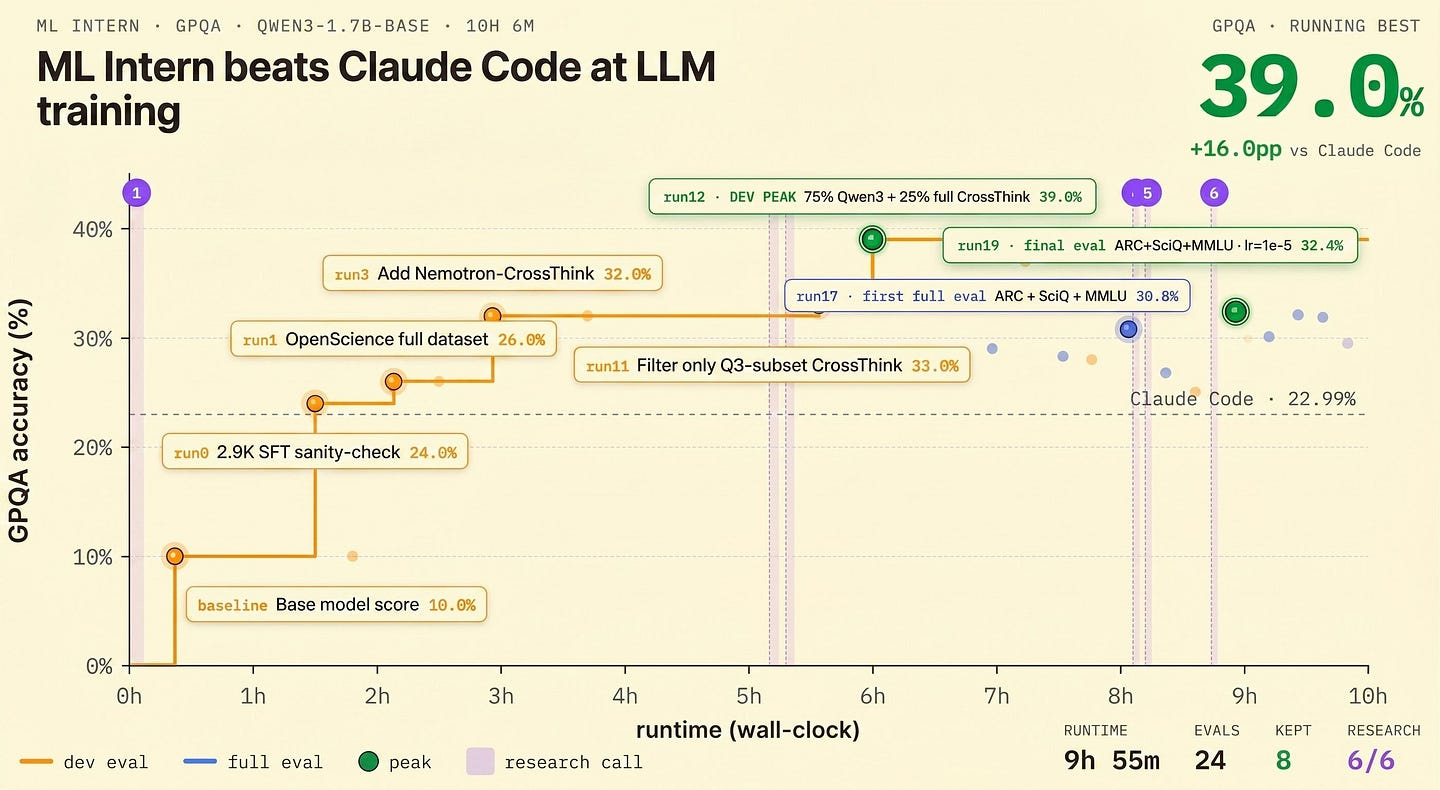
Hugging Face released ml-intern on April 21, 2026 — an open-source autonomous agent that runs the full LLM post-training loop, from literature review to evaluation. In benchmark testing, the agent took a Qwen3-1.7B model from a roughly 10% baseline to 32% on GPQA in under 10 hours on a single H100, surpassing Claude Code’s 22.99% on the same task and demonstrating that an open agent stack can match the kind of automated research workflows previously confined to frontier labs.
Intermediate
What ml-intern Does
ml-intern is pitched as an “open-source ML engineer that reads papers, trains models, and ships ML models.” Built on Hugging Face’s smolagents framework, it strings together the steps a human ML researcher would normally do by hand: searching arXiv and Hugging Face Papers for relevant literature, traversing citation graphs to discover datasets, writing and launching training scripts, monitoring evaluation outputs, diagnosing failures (including reward collapse during RLHF), and iterating until performance improves. When local compute is unavailable, the agent can spin up runs on Hugging Face Jobs, and uses Trackio for open-source experiment tracking.
The agent ships in two flavors — an interactive CLI and a headless mode that takes a single prompt — plus a mobile and desktop web app. A typical headless invocation looks like:
ml-intern --model anthropic/claude-opus-4-6 "fine-tune llama on my dataset"Benchmark: Qwen3-1.7B on GPQA
The headline result is a self-improvement run on Qwen3-1.7B against the GPQA scientific reasoning benchmark. With no human intervention beyond the initial goal, ml-intern raised the model’s GPQA score from a starting point of roughly 8.5–10% to 32% in under 10 hours, crossing 27.5% in just over three hours. By comparison, Claude Code’s reported GPQA score on the same task sits at 22.99%. The run was conducted on a single H100 GPU, making the result reproducible for any researcher with modest cloud compute.
A second case study demonstrates more open-ended judgment. Pointed at a healthcare fine-tuning task, the agent surveyed available medical datasets, decided their quality was insufficient for reliable training, and instead wrote a script to generate synthetic examples covering edge cases like medical hedging language and multilingual emergency-response scenarios — then upsampled and evaluated against HealthBench.
Architecture
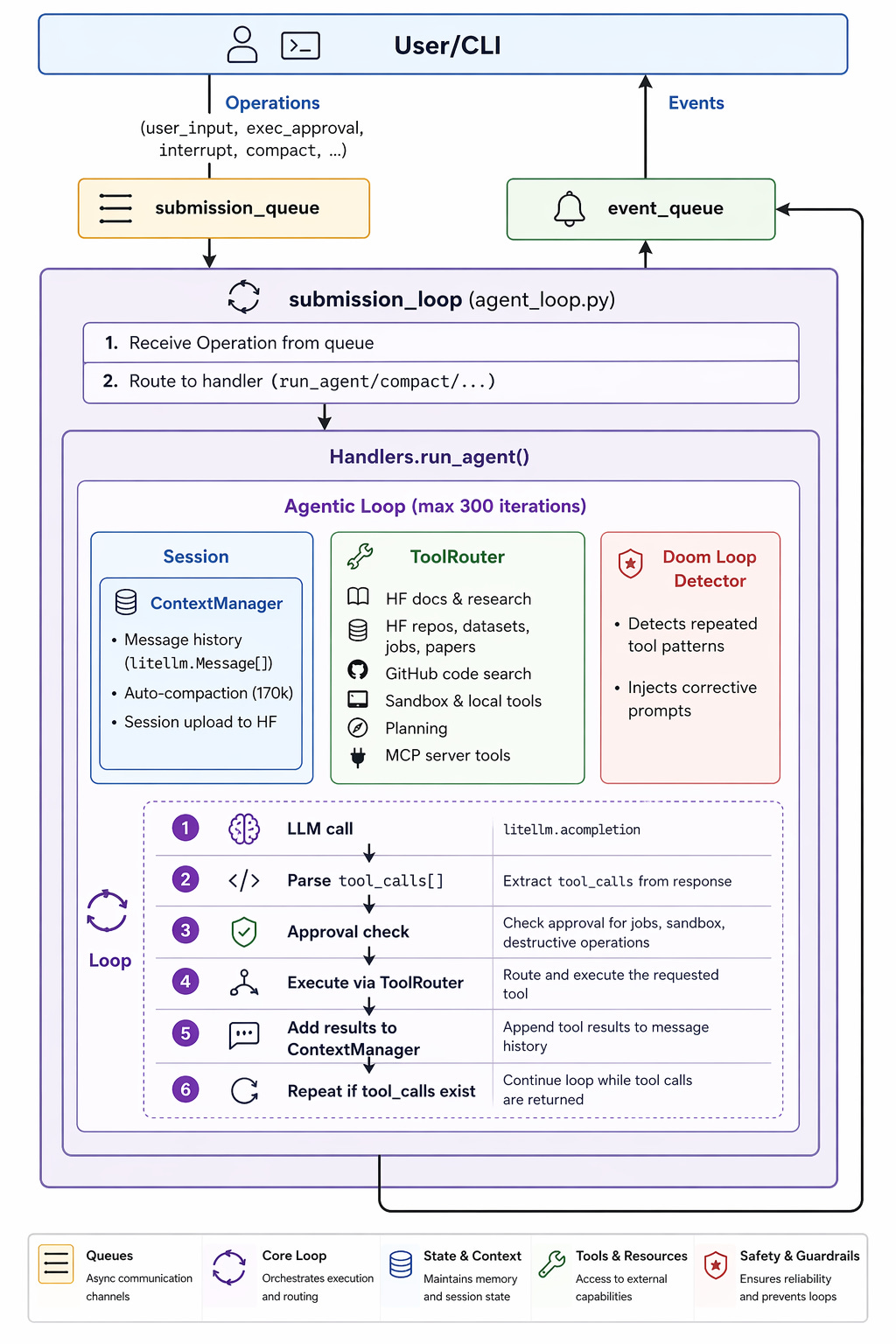
Under the hood, ml-intern uses a submission-queue agentic loop with up to 300 iterations. Key components include a ContextManager that maintains message history with auto-compaction at 170k tokens, a ToolRouter that dispatches calls to Hugging Face docs, repos, datasets, jobs, papers, GitHub code search, and external MCP servers, and a doom-loop detector that watches for repeated tool patterns and injects corrective prompts. Sensitive operations — anything that launches paid jobs or runs destructive commands — pause for explicit user approval.
The codebase is roughly 73% Python and 27% TypeScript (frontend), and is installed via the standard uv toolchain. Required tokens include HF_TOKEN, GITHUB_TOKEN, and an API key for the underlying model provider (Anthropic or OpenAI). At time of writing, the repo has 6.8k stars and 633 forks.
What This Means
The pitch from Hugging Face’s Aksel Joonas Reedi is direct: “Introducing ml-intern, the agent that just automated the post-training team.” That framing matters. Closed agents like Claude Code and OpenAI’s Codex have demonstrated strong coding performance, but ml-intern is the first open-source release explicitly built around the post-training research loop — not generic software engineering. The combination of native Hugging Face Hub access, on-platform compute (HF Jobs), and reproducible experiment tracking (Trackio) lowers the barrier for academic labs and independent researchers who want to automate fine-tuning, dataset distillation, or RLHF experiments without renting closed infrastructure.
It also raises familiar questions about where automation stops. The healthcare example — an agent unilaterally deciding to generate synthetic data when datasets look weak — is exactly the kind of judgment call that, in a real research workflow, deserves human review. ml-intern’s approval gates are a reasonable first answer, but how teams actually integrate autonomous experimentation into their research practice is the more interesting open question.
Related Coverage
- OpenAI Releases GPT-5.5: Agentic Coding Ceiling Tops 14 Benchmarks — closed-model agentic coding context for the Claude Code comparison
- Moonshot AI Releases Kimi K2.6 with 256K Context and 300-Agent Swarms — another open-weight agentic system pushing multi-step autonomy
- Qwen3.6-27B: A Dense 27B Model That Beats a 397B MoE on Coding — context on the Qwen family that ml-intern fine-tuned in its benchmark run
Sources
- huggingface/ml-intern on GitHub — official repository, install instructions, architecture
- MarkTechPost — Hugging Face Releases ml-intern — launch coverage and benchmark detail
- To Data & Beyond — Automating LLM Post-Training with Hugging Face’s ml-intern — workflow walkthrough and screenshots
- ml-intern Space on Hugging Face — hosted demo
- EdTech Innovation Hub — ML Intern beats Claude Code on scientific reasoning


 沪公网安备31011502017015号
沪公网安备31011502017015号