Google Releases Gemini 3.1 Flash TTS with 200+ Audio Tags


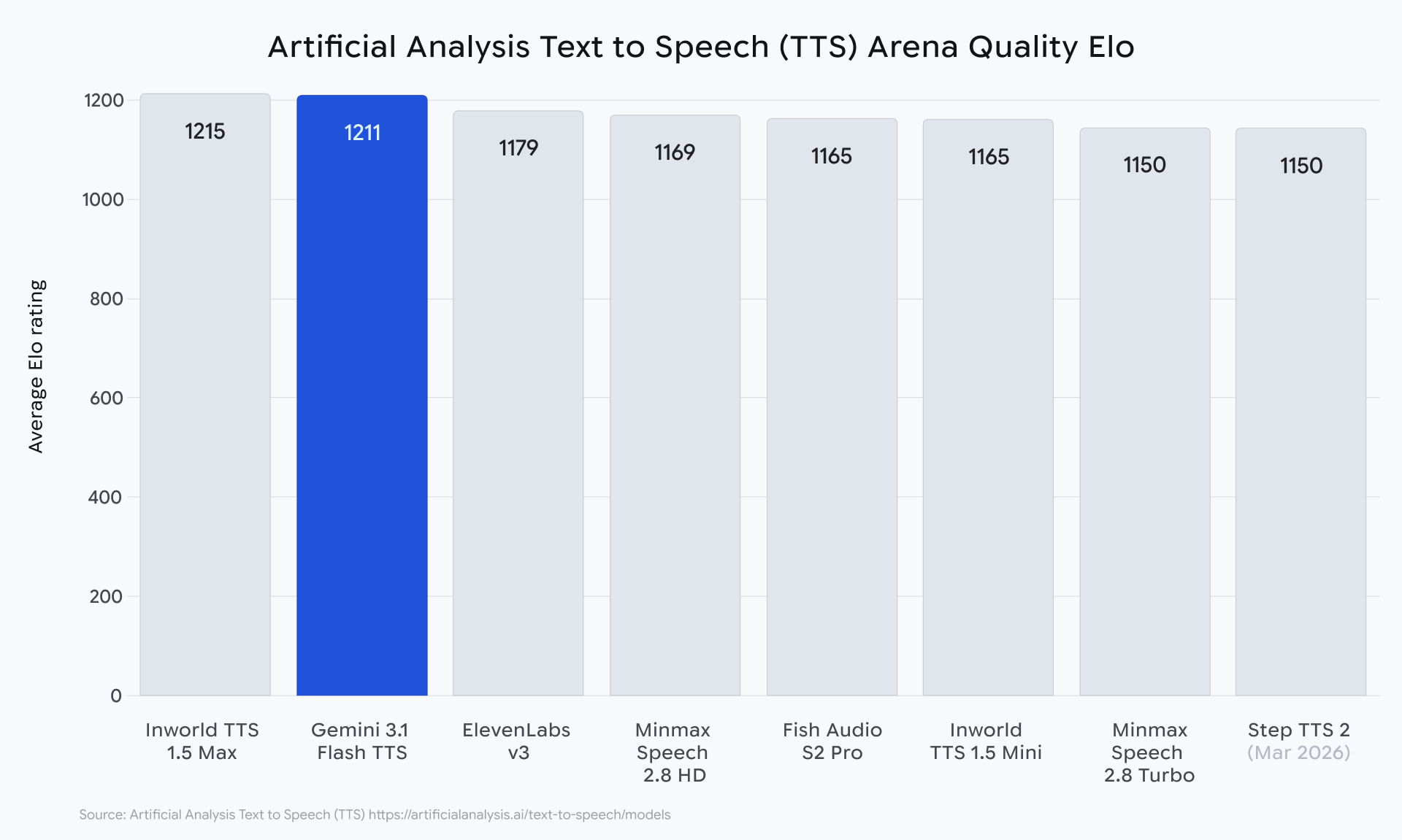
On April 15, 2026, Google DeepMind released Gemini 3.1 Flash TTS — a text-to-speech model that introduces more than 200 granular audio tags for steering vocal style, tone, pacing, and accent, and tops the Artificial Analysis TTS leaderboard with an Elo score of 1,211. The preview is available through the Gemini API, Google AI Studio, Vertex AI, and Google Vids, with support for 70+ languages and native multi-speaker dialogue.
Intermediate

What’s New
Gemini 3.1 Flash TTS is Google’s most expressive speech model to date, focused on controllability rather than raw scale. Developers can embed natural-language audio tags directly into the input text — covering delivery style (whispering, excited, calm), pacing (fast, slow), accent, and even scene direction for multi-speaker scripts. Tags can be placed inline mid-sentence to shift expression on the fly, and speaker-level tags let a single prompt produce a dialogue with distinct voices without separate API calls.
The model supports more than 70 languages and is positioned by Google as offering a strong quality-to-cost ratio. The paid tier is priced at $1.00 per million input tokens and $20.00 per million audio output tokens, with a batch mode offering a 50% discount. A free tier is available for experimentation, though Google notes that free-tier data may be used for product improvement.
Benchmarks
On the Artificial Analysis TTS leaderboard — a blind human-preference evaluation — Gemini 3.1 Flash TTS scored 1,211 Elo, placing it among the top entries for expressive speech synthesis. Google highlights its position in what the leaderboard calls the “most attractive quadrant” for combined quality and cost.
Safety and Availability
Every audio clip generated by Gemini 3.1 Flash TTS is watermarked with SynthID, Google’s imperceptible identifier for AI-generated content. The watermark is designed to survive common audio transformations while preserving audible quality, giving platforms a way to detect and label synthetic speech.
Developers can access the preview via the Gemini API and Google AI Studio; enterprises get it through Vertex AI; and Google Workspace users can use it inside Google Vids for narration and voiceovers. The release was led by Vilobh Meshram (Senior Product Manager) and Max Gubin (Principal Research Engineer) on the Google DeepMind speech team.
What This Means
Controllable TTS is becoming the competitive frontier. With Mistral’s Voxtral TTS and Alibaba’s Qwen3-TTS targeting open-weight deployments, and ElevenLabs defending the commercial voice market, Google’s play is to bundle expressive control directly into the Gemini API surface developers already use for text and multimodal work. The 200+ audio tags make Gemini 3.1 Flash TTS particularly well-suited to audiobook production, video dubbing, and conversational agents where emotional range matters more than sheer naturalness.
Related Coverage
- Google Releases Gemini 3.1 Pro with 2× Reasoning Performance — the reasoning sibling in the 3.1 family.
- Google Launches Gemini Embedding 2 — the multimodal embedding counterpart.
- Voxtral TTS: Mistral’s Open-Weight TTS — an open-weight alternative in the same space.


 沪公网安备31011502017015号
沪公网安备31011502017015号