GLM-5.2: Z.ai’s Open-Weights Coder Beats GPT-5.5 at 1/6 the Cost


On June 13, 2026, Z.ai (formerly Zhipu AI) released GLM-5.2 — a 753-billion-parameter open-weights Mixture-of-Experts model built for long-horizon, autonomous coding. The headline claim is striking: GLM-5.2 edges past OpenAI’s GPT-5.5 on several multi-step engineering benchmarks while costing roughly one-sixth as much to run. The full weights ship under an unrestricted MIT license on Hugging Face, continuing Z.ai’s push to keep frontier-grade coding models in the open.
Intermediate


What’s New in GLM-5.2
GLM-5.2 is the third major release in the GLM-5 line, following GLM-5.1 in April. It keeps the sparse Mixture-of-Experts (MoE) design — 753 billion total parameters, but only about 40 billion activated per token — so inference cost stays far below what a dense model of that size would demand. The big architectural change is on the attention side: GLM-5.2 uses a multimodal sparse attention scheme with an “IndexShare” mechanism that reuses the same indexer across every four sparse-attention layers, cutting per-token compute by roughly 2.9× at full context length.
That efficiency unlocks the model’s standout feature: a stable 1-million-token context window, up from 200,000 in GLM-5.1. Combined with auto-compaction, it lets the model sustain “plan, execute, test, fix, optimize” agentic loops over very long sessions without losing track of earlier state. Developers can also pick between two thinking-effort levels — “High” and “Max” — to trade speed against depth on a per-task basis.
The Benchmarks
Z.ai evaluated GLM-5.2 against GLM-5.1, Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro across eight coding and reasoning suites, with every model run at maximum thinking effort. GLM-5.2 leads or ties on most of the long-horizon coding tasks.

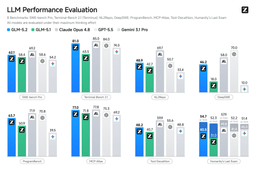
Highlights from Z.ai’s reported numbers:
- SWE-bench Pro: 62.1 — ahead of GLM-5.1 (58.4) and Claude Opus 4.8 (69.2 trails on some configs; GLM leads the open field)
- Terminal-Bench 2.1: 81.0 — the top score in the comparison
- MCP-Atlas: 77.0 and Tool-Decathlon: 48.2 — strong agentic tool-use results
- AIME 2026: 99.2 and GPQA-Diamond: 91.2 — competitive reasoning numbers
On FrontierSWE, Z.ai reports GLM-5.2 finishing about one percent ahead of GPT-5.5 — a narrow win, but a notable one for an openly licensed model running at a fraction of the cost.
What This Means
The most consequential part of this release may be the pricing pressure. Access launched first through Z.ai’s GLM Coding Plan, with subscription tiers starting around $12.60 per month and the model integrating as a drop-in replacement in tools like Claude Code, Cline, and OpenClaw. If an MIT-licensed model can match a closed frontier model on agentic coding for roughly a sixth of the cost, the economics of paying premium API rates for long-running coding agents start to look very different.
For students and researchers, the open weights matter just as much. The full weights are already published on Hugging Face under an MIT license with no regional restrictions, which means GLM-5.2 can be downloaded, fine-tuned, and deployed commercially without permission or royalties — a meaningful option for anyone studying long-context behavior, agentic loops, or sparse-attention efficiency on real frontier-scale weights. Access initially rolled out through the GLM Coding Plan, with the API and chatbot following alongside the open release.
Related Coverage
- GLM-5.1: Z.ai’s Open-Weight Model Takes #1 on SWE-Bench Pro — the April predecessor that set the stage for the 5.2 release
- GLM-OCR: Z.ai’s 0.9B Model Takes the Top Spot on Document Understanding Benchmarks — Z.ai’s compact open document model
Sources
- GLM-5.2 model card — zai-org on Hugging Face
- VentureBeat — Z.ai’s open-weights GLM-5.2 beats GPT-5.5 on long-horizon coding benchmarks for 1/6th the cost
- Crypto Briefing — Z.ai’s GLM-5.2 outperforms GPT-5.5 on coding benchmarks at one-sixth the cost
- Build Fast with AI — GLM-5.2 Review 2026
- Surf AI — Open-Weight GLM-5.2 Puts Real Pressure on Closed-Model Pricing


 沪公网安备31011502017015号
沪公网安备31011502017015号