GLM-5.1: Z.ai’s Open-Weight Model Takes #1 on SWE-Bench Pro


On April 7, 2026, Z.ai (formerly Zhipu AI) released GLM-5.1 — a 754-billion-parameter open-weight Mixture-of-Experts model that claims the #1 position on SWE-Bench Pro with a score of 58.4%, edging out Claude Opus 4.6 (57.3%). Licensed under MIT and designed for agentic engineering, GLM-5.1 can autonomously sustain coding tasks for up to eight hours across hundreds of iterations.
Intermediate
What’s New in GLM-5.1
GLM-5.1 is a post-training upgrade to GLM-5, built on a Dynamic Sparse Attention (DSA) MoE architecture with approximately 40 billion active parameters per token. The model is laser-focused on two areas: coding and agentic tool use.
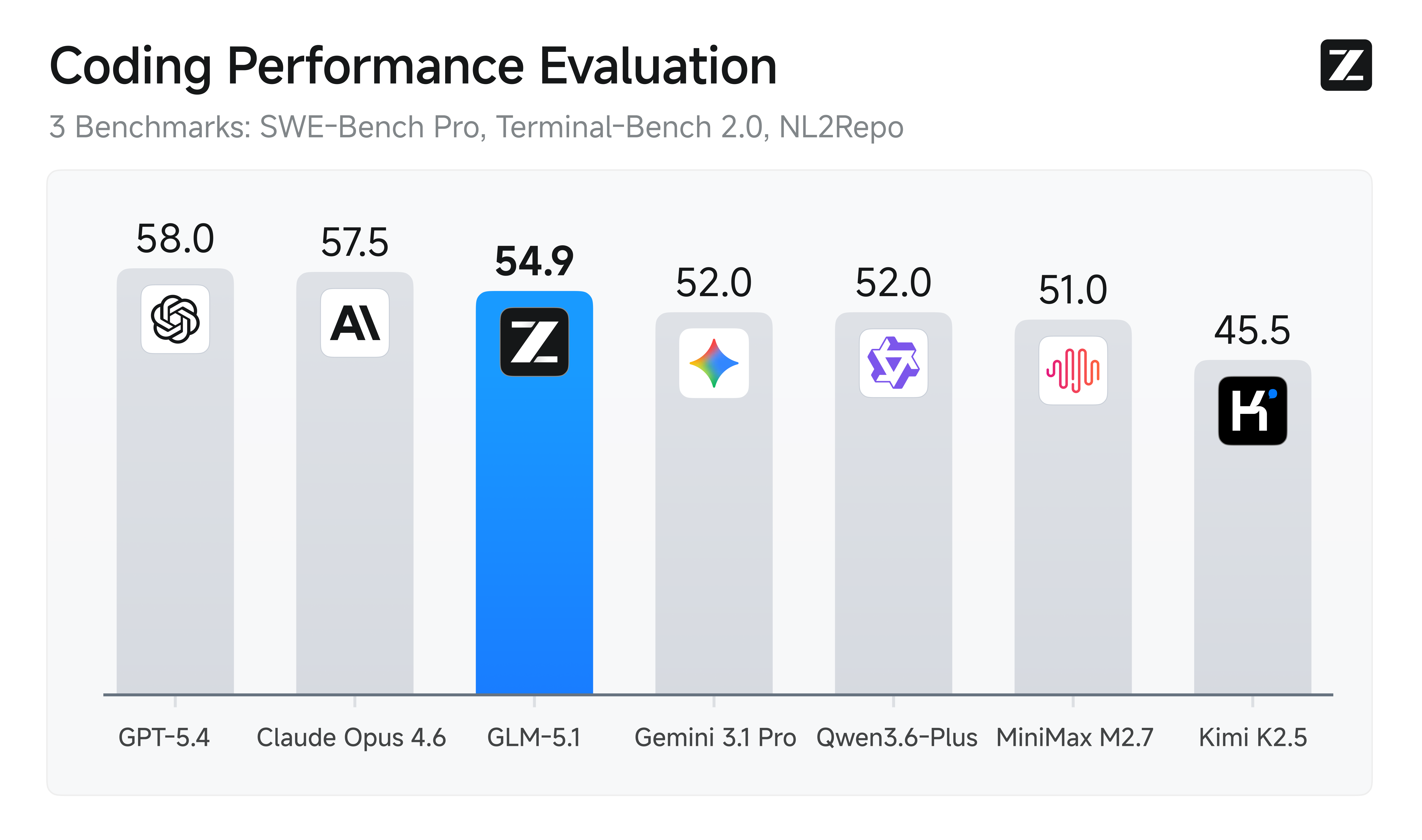
On coding benchmarks, GLM-5.1 leads across multiple evaluations:
- SWE-Bench Pro: 58.4% — the highest score among all models, open or closed
- CyberGym: 68.7% — top score for cybersecurity tasks
- BrowseComp: 68.0% — best in web browsing comprehension
- Terminal-Bench 2.0: 63.5% on the Terminus-2 track
- NL2Repo: 42.7% for natural-language-to-repository generation
Math and reasoning capabilities remain strong: 95.3% on AIME 2026, 86.2% on GPQA-Diamond, and 83.8% on IMOAnswerBench.
Agentic Engineering at Scale
What sets GLM-5.1 apart is its ability to sustain long-horizon agentic tasks. In demonstrations, the model autonomously built a complete Linux desktop system over an eight-hour session, performing 655 iterations of planning, execution, testing, and optimization. In another test, it increased vector database query throughput to 6.9× the initial production version through iterative experimentation.
The model supports deployment through SGLang (v0.5.10+), vLLM (v0.19.0+), xLLM, Transformers, and KTransformers. Its MIT license places no restrictions on commercial use.
What This Means
GLM-5.1 represents a milestone for Chinese open-source AI: a model from Z.ai that outperforms the best closed-source competitors on SWE-Bench Pro, the industry’s most respected coding benchmark. For developers and researchers, the MIT license and broad framework support make it immediately deployable — no API key required.
Related Coverage
- GLM-5: Zhipu AI Ships a 744B Open-Weight Frontier Model — the predecessor model
- GLM-4.7-Flash: Z.ai’s Efficient 30B MoE Model for Coding and Agents
- GLM-OCR: Z.ai’s 0.9B Model Takes the Top Spot on Document Understanding Benchmarks


 沪公网安备31011502017015号
沪公网安备31011502017015号