DeepSeek Releases V4: Open-Source 1.6T MoE with 1M Context


DeepSeek has launched V4, its newest flagship open-source language model, exactly one year after the V3/R1 releases that rattled Silicon Valley. Announced on April 24, 2026, the V4 family ships in two Mixture-of-Experts variants — a 1.6-trillion-parameter V4-Pro and a leaner 284-billion-parameter V4-Flash — both supporting a 1-million-token context window and both released with open weights under permissive licenses.
Intermediate
What Was Released
The V4 series comprises two MoE language models that share the same core architecture but target different deployment budgets:
- DeepSeek-V4-Pro — 1.6T total parameters, 49B activated per token.
- DeepSeek-V4-Flash — 284B total parameters, 13B activated per token.
Both models support up to 1 million input tokens and up to 384K tokens of output. Weights are available on Hugging Face, and the API is live at DeepSeek-compatible endpoints that speak both the OpenAI ChatCompletions and Anthropic protocols. Published API pricing is $1.74 / $3.48 per million input/output tokens for V4-Pro and $0.14 / $0.28 for V4-Flash — roughly an order of magnitude below comparable closed frontier models.
Architecture and Efficiency Gains
DeepSeek describes V4 as a genuine generational step rather than a refresh of V3.2. Three ideas drive the jump:
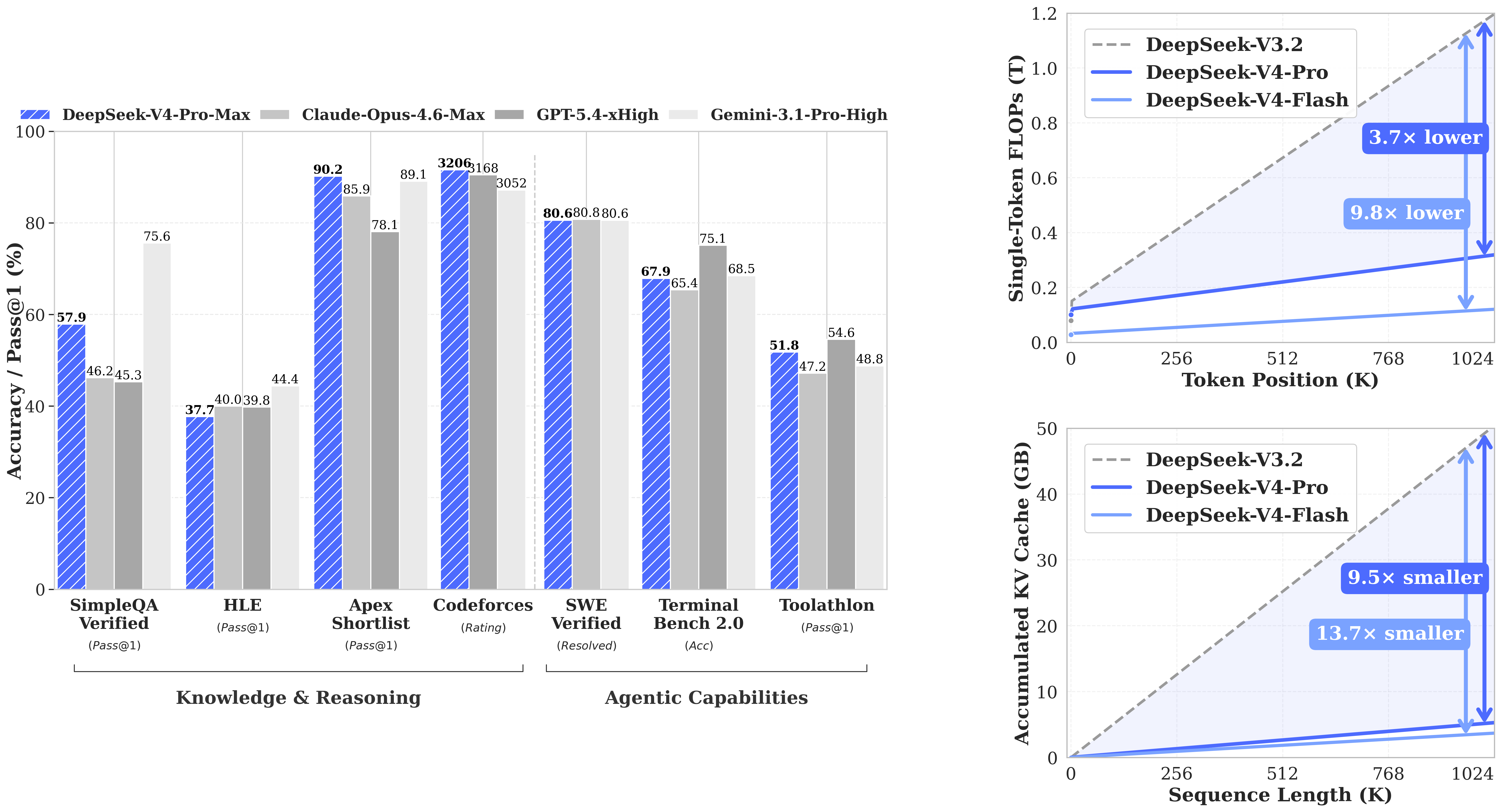
- Hybrid Attention — V4 combines Compressed Sparse Attention (CSA) with Heavily Compressed Attention (HCA) to keep long-context inference tractable. At 1M-token context, V4-Pro reports needing only 27% of the single-token inference FLOPs and 10% of the KV cache of V3.2.
- Manifold-Constrained Hyper-Connections (mHC) — a residual-propagation scheme that DeepSeek says stabilizes signal flow through very deep MoE stacks.
- Muon optimizer + FP4/FP8 mixed precision training — MoE experts are trained in FP4 while most other parameters use FP8. The model was pre-trained on more than 32 trillion tokens.
V4 also exposes three reasoning modes: non-think for fast responses, think-high for conscious logical analysis, and think-max for the model’s full chain-of-thought budget (DeepSeek recommends pairing think-max with 384K+ token context).
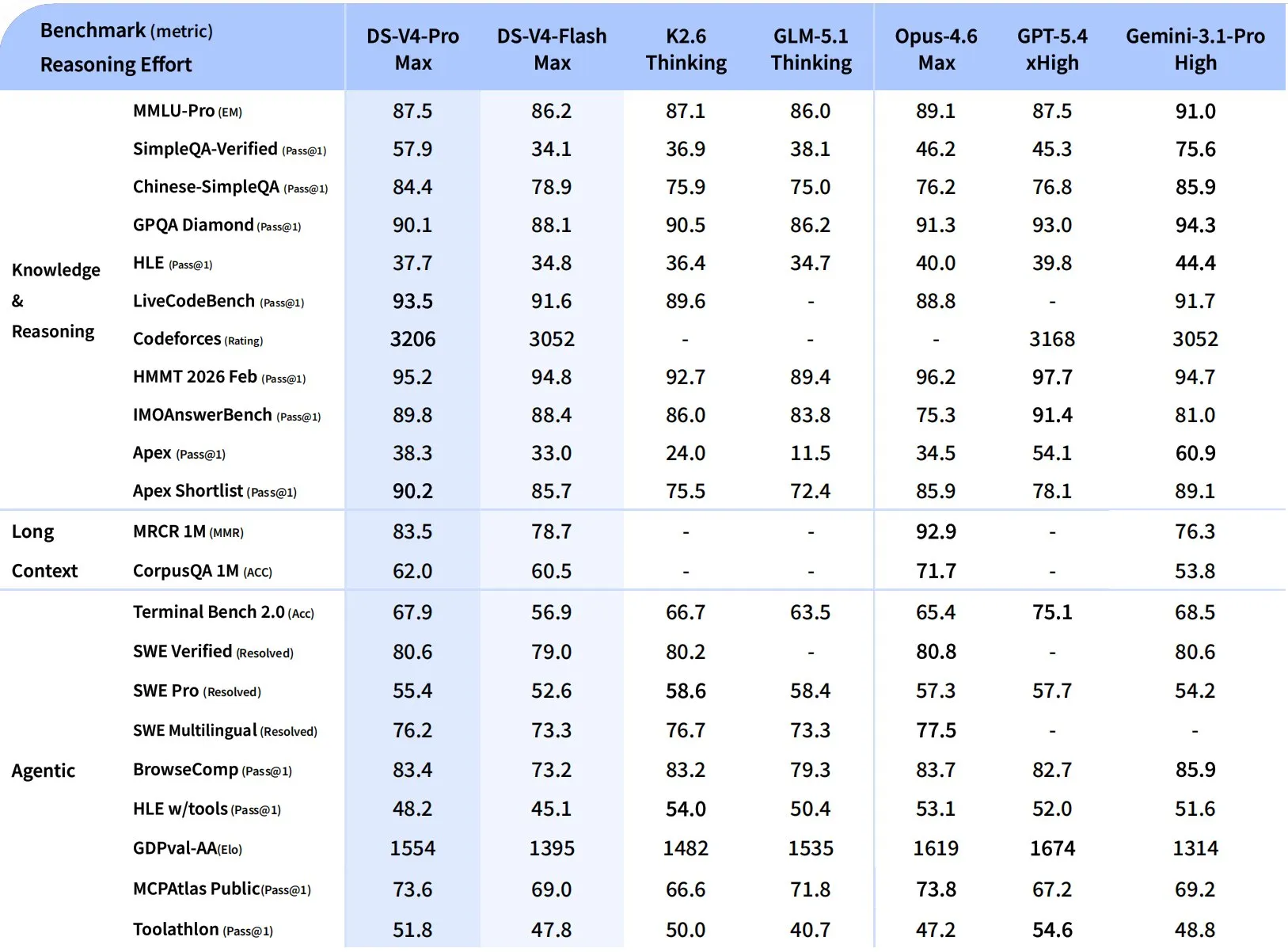
Benchmarks
On the scorecards DeepSeek published alongside the release, V4-Pro-Max posts numbers that are competitive with — and in places ahead of — proprietary frontier systems:
- MMLU-Pro: 87.5%
- SimpleQA-Verified: 57.9%
- LiveCodeBench: 93.5% (vs. Kimi K2.6 at 89.6%)
- Codeforces rating: 3206 (vs. GPT-5.4 at 3168)
- HMMT 2026 Feb (math): 95.2%
- MRCR 1M (long-context recall): 83.5%
- SWE-bench Verified: 80.6%
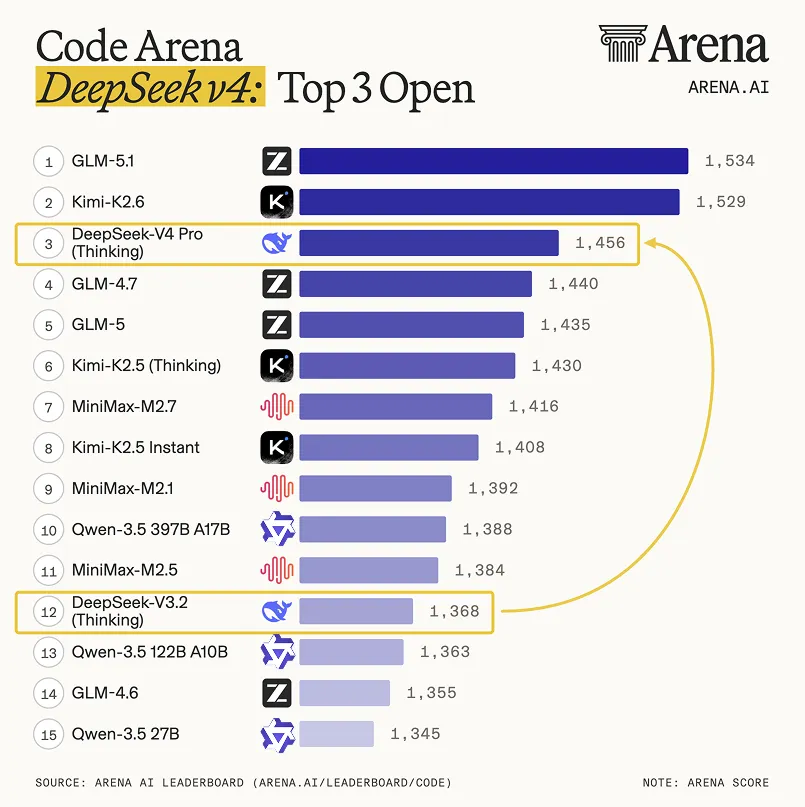
On the LM-Arena Code leaderboard, V4-Pro Thinking currently sits at #3 among open models with an Elo of 1,456 — an 88-Elo gain over V3.2. V4 still trails Anthropic’s Opus 4.6 on MRCR 1M long-context recall (92.9%) and trails Kimi K2.6 on the newer SWE-bench Pro.
What This Means
V4 sharpens the pattern DeepSeek established with V3 and R1: ship an open-weights model whose reported benchmarks sit in the same neighborhood as closed frontier systems, at a fraction of the API cost, and with architectural ideas (sparse/compressed attention, hyper-connections, FP4 expert training) that the rest of the community can inspect and adopt. The inference-efficiency claims are particularly consequential — if the 27%-FLOPs and 10%-KV-cache numbers hold at 1M-token context, V4-Pro makes long-context agentic workloads meaningfully cheaper to serve than prior-generation MoE designs.
Questions worth watching over the next few weeks: how the independent reproductions of LiveCodeBench and SWE-bench numbers land, how V4-Flash performs on commodity GPUs, and how quickly the Hugging Face weights show up in hosted-inference providers. The April 24 announcement is the starting gun, not the finish line.
Related Coverage
- Anthropic Exposes Industrial-Scale Distillation Attacks by DeepSeek, Moonshot, and MiniMax — February 2026 disclosure that touched off a new round of debate over how Chinese labs train their models.
- DeepSeek Unveils DeepSeekV3.1 Terminus — the September 2025 V3.1 update that set the baseline V4 is being measured against.
- DeepSeek-V3.1 Enhances AI Capabilities with Anthropic API Compatibility — the dual-protocol API pattern V4 continues.


 沪公网安备31011502017015号
沪公网安备31011502017015号