NVIDIA Releases gpt-oss-puzzle-88B: Up to 2.82× Faster Reasoning on a Single H100


On March 26, 2026, NVIDIA released gpt-oss-puzzle-88B — a deployment-optimized version of OpenAI’s gpt-oss-120B reasoning model that delivers up to 2.82× faster inference while matching or exceeding the original model’s accuracy. Created using NVIDIA’s Puzzle neural architecture search framework, the 88-billion-parameter model fits on a single H100 GPU and represents a significant step forward in making frontier reasoning models practical for production deployment.
Advanced
From 120B to 88B: How Puzzle Optimizes Without Losing Accuracy
The gpt-oss-puzzle-88B model was created using Puzzle, NVIDIA’s post-training neural architecture search (NAS) framework designed to optimize large language models for inference efficiency. The approach combines three key techniques:
- Heterogeneous MoE expert pruning — Rather than uniformly pruning experts across all layers, Puzzle retains more experts in early layers (where they matter most) and aggressively prunes later layers. This reduces the model from 120B to 88B parameters (~73% of the original) while preserving critical reasoning pathways.
- Selective window attention — Roughly 40% of attention layers are converted from full-context attention to 8K window attention, significantly reducing KV-cache memory requirements without degrading long-context performance up to 128K tokens.
- FP8 KV-cache quantization — Calibrated quantization scales compress the key-value cache, approximately doubling token capacity and enabling faster attention kernels.
After architecture optimization, the model undergoes knowledge distillation on 84 billion tokens at 128K sequence length using the Megatron-LM framework, followed by multi-environment reinforcement learning across math, coding, and reasoning tasks.
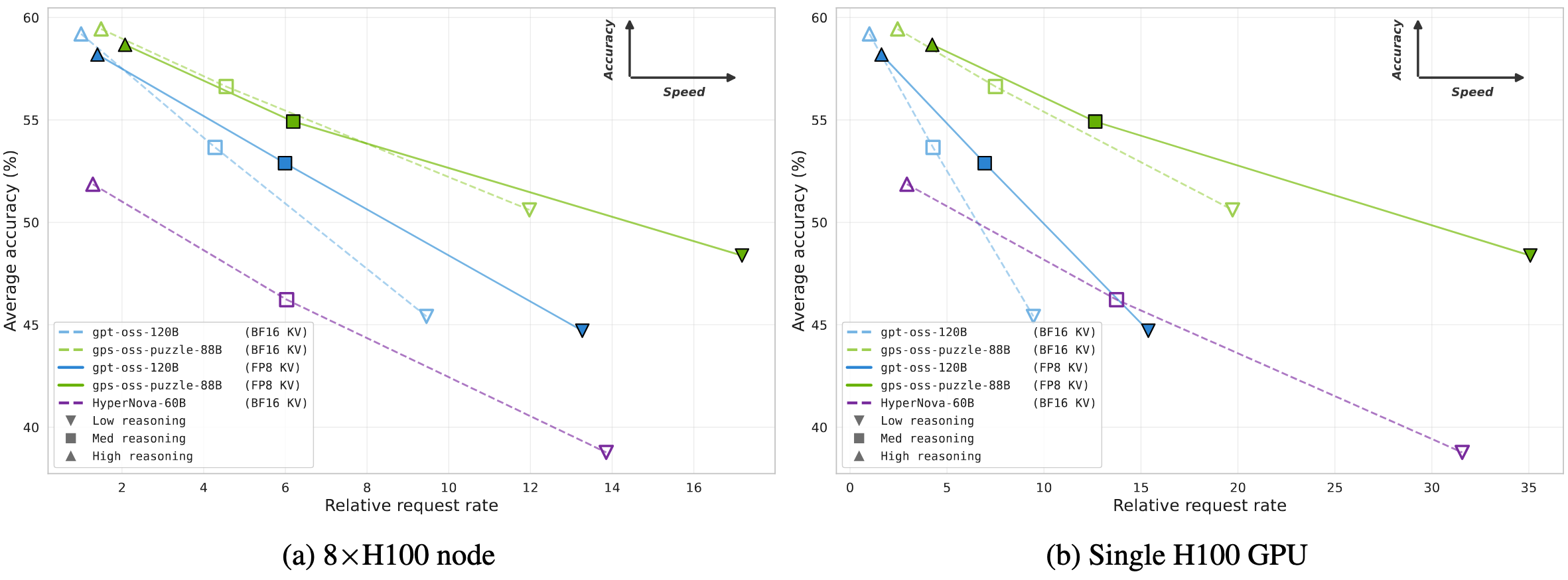
Benchmark Results: Faster and Just as Smart
The results are striking. Across NVIDIA’s evaluation suite — including MMLU-Pro, GPQA-Diamond, AIME25, SciCode, and RULER 128K — the optimized model achieves accuracy retention between 100.8% and 108.2% compared to the parent gpt-oss-120B, meaning it actually improves on several benchmarks despite being 27% smaller.
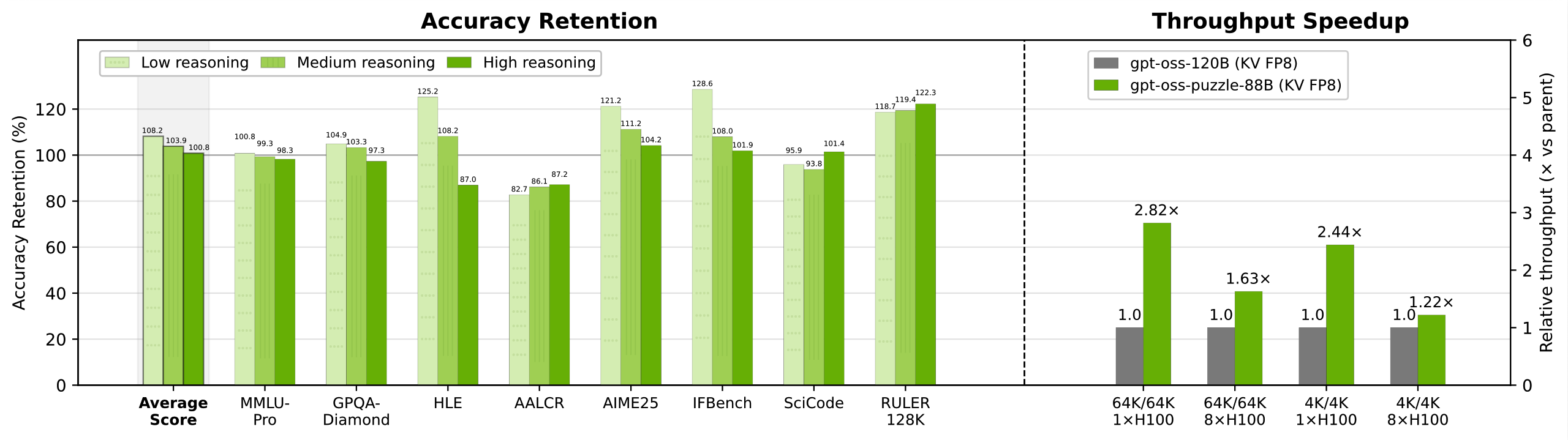
The throughput gains depend on the deployment scenario:
| Configuration | Throughput Speedup |
|---|---|
| Long-context (64K/64K) on 8×H100 | 1.63× |
| Short-context (4K/4K) on 8×H100 | 1.22× |
| Long-context on single H100 | 2.82× |
| Short-context on single H100 | 2.44× |
The single-GPU results are particularly noteworthy: the model achieves nearly 3× throughput improvement, making frontier-class reasoning accessible on a single H100 — hardware that many research labs and enterprises already have.
Reasoning Effort Control
Like its parent, gpt-oss-puzzle-88B supports three reasoning effort levels — low, medium, and high — allowing developers to trade compute for accuracy on a per-request basis. This is especially relevant for cost-aware production deployments where not every query requires deep multi-step reasoning. The model is compatible with standard inference stacks including Hugging Face Transformers (v4.57.3+) and vLLM, and can be served with a single vllm serve command.
What This Means
NVIDIA’s Puzzle framework demonstrates that post-training architecture optimization can yield substantial inference savings without the typical accuracy trade-offs associated with model compression. The approach is detailed in an accompanying research paper and builds on NVIDIA’s earlier Puzzle work for dense models (arXiv: 2411.19146).
The release also reflects NVIDIA’s growing role as a bridge between open-weight model providers and production deployment. OpenAI released gpt-oss-120B and gpt-oss-20B in August 2025 as its first open-weight models since GPT-2 — and NVIDIA’s optimization pipeline is now turning these models into more practical deployment targets, particularly for organizations running H100 or B200 infrastructure.
The model is available now on Hugging Face under the NVIDIA Open Model License, which permits commercial use.
Related Coverage
- NVIDIA Launches Nemotron Coalition to Build Open Frontier AI Models — NVIDIA’s collaborative initiative for open-weight model development
- NVIDIA Nemotron 3 Super: 120B Hybrid Model Activates Only 12B Parameters — another NVIDIA approach to efficient large-model inference


 沪公网安备31011502017015号
沪公网安备31011502017015号