Google’s TurboQuant Cuts LLM Memory 6x with Zero Accuracy Loss


On March 25, 2026, Google Research introduced TurboQuant — a new compression algorithm that reduces LLM key-value (KV) cache memory by 6x and delivers up to 8x inference speedup on NVIDIA H100 GPUs, all with zero accuracy loss. The algorithm, set to be presented at ICLR 2026, could reshape how organizations deploy large language models by dramatically cutting the memory bottleneck that drives infrastructure costs.
Advanced


The KV Cache Problem
Every time a large language model processes a long conversation or document, it stores intermediate computations in a key-value cache. As context windows grow — GPT-5.4 now supports 1 million tokens, Gemini 3.1 Pro also handles 1 million — this cache becomes the dominant memory consumer during inference. A single long-context request can occupy gigabytes of GPU memory, limiting how many users a single GPU can serve simultaneously and inflating cloud computing costs.
Previous approaches to KV cache compression typically required fine-tuning, introduced measurable accuracy degradation, or added overhead that offset their memory savings. TurboQuant claims to solve all three problems at once.
How TurboQuant Works
TurboQuant combines two complementary techniques into a two-stage compression pipeline:
Stage 1 — PolarQuant (high-quality compression): Instead of quantizing vectors in standard Cartesian coordinates, PolarQuant first randomly rotates the data vectors and then converts them to polar coordinates, expressing each pair of dimensions as a radius and an angle. Because the angular distribution after rotation is predictable and concentrated, PolarQuant can quantize directly on a fixed circular grid without the per-block normalization constants that traditional methods require. This eliminates 1–2 bits of overhead per value that normalization typically adds — overhead that becomes significant at extreme compression rates. PolarQuant will be presented at AISTATS 2026.
Stage 2 — QJL (error correction): Quantized Johnson-Lindenstrauss applies the Johnson-Lindenstrauss transform to the residual error left after PolarQuant, then reduces each resulting value to a single sign bit (+1 or −1). This 1-bit error-correction layer eliminates bias in inner product estimates with zero additional memory overhead, using a specialized estimator to maintain attention score accuracy. QJL was first presented at AAAI 2024.
Crucially, TurboQuant is data-oblivious — it requires no training, fine-tuning, or calibration on specific datasets. You can apply it to any model at inference time as a drop-in optimization.
Benchmark Results
Google tested TurboQuant across multiple open-source models (Llama-3.1-8B, Mistral-7B, Gemma) on a comprehensive suite of long-context benchmarks:

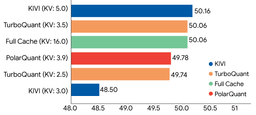
- LongBench (question answering, code generation, summarization): TurboQuant matched or outperformed the KIVI baseline across all tasks while using 6x less KV cache memory.
- Needle In A Haystack: Achieved perfect recall scores, identical to uncompressed models.
- ZeroSCROLLS, RULER, L-Eval: Perfect downstream results across all benchmarks with 3-bit quantization — no accuracy loss detected.

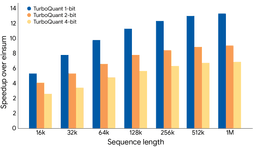
On NVIDIA H100 GPUs, 4-bit TurboQuant delivered an 8x speedup in computing attention logits compared to unquantized 32-bit keys.
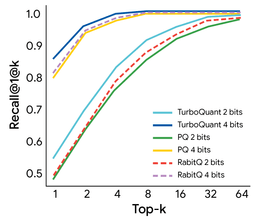
Beyond LLM inference, TurboQuant also demonstrated state-of-the-art results in vector search on the GloVe dataset (d=200), achieving superior recall ratios compared to established baselines like Product Quantization (PQ) and RabbiQ across top-k retrieval tasks.

Why This Matters
The practical implications are significant. A 6x reduction in KV cache memory means a GPU that previously served one long-context session could potentially serve six — or handle context lengths six times longer on the same hardware. The 8x inference speedup on H100s translates directly to lower latency and reduced cost-per-token for API providers.
Unlike many compression techniques that trade accuracy for efficiency, TurboQuant’s zero-loss property makes it viable for production deployments where output quality cannot be compromised. Its data-oblivious nature means it can be applied to new models immediately without retraining — a critical advantage as the pace of model releases accelerates.
The research was led by Amir Zandieh (Research Scientist) and Vahab Mirrokni (VP and Google Fellow), with collaborators including Praneeth Kacham, Majid Hadian, Insu Han, Majid Daliri, Lars Gottesbüren, and Rajesh Jayaram.
Related Coverage
- Google Launches Gemini Embedding 2: Its First Multimodal Embedding Model — Google’s latest embedding model with multimodal vector representations
- Google Releases Gemini 3.1 Pro with 2x Reasoning Performance — the 1M-token context model that benefits from KV cache compression
- Advancing LLM Training: Introducing NVFP4 for Efficient Pretraining — NVIDIA’s complementary approach to quantized AI computation